

Agents and Context
For long-running, complex tasks, an agentic system often follows a flow roughly like this:
- Understand the high-level goal, and decompose it into tasks
- Generate a viable 'todo list' from the decomposed tasks
- Iterate through the todo list, 'completing' tasks by executing tool calls, making observations, and repeating until the item is 'done'
- Stop execution once there are no remaining items to complete
For non-trivial goals (e.g. 'understand the existing database schema, and author and execute safe migrations to go from that current state to the database schema described by diagram A and descriptive PDF B'), even leading-edge LLMs with large (500k-1M token) context windows are likely to exhaust that context before the task is completed. Much of this is due to the large amount of tokens from 'observed' tool results - a whopping 83.9% compared to action tokens (e.g. tool calls) and reasoning traces.
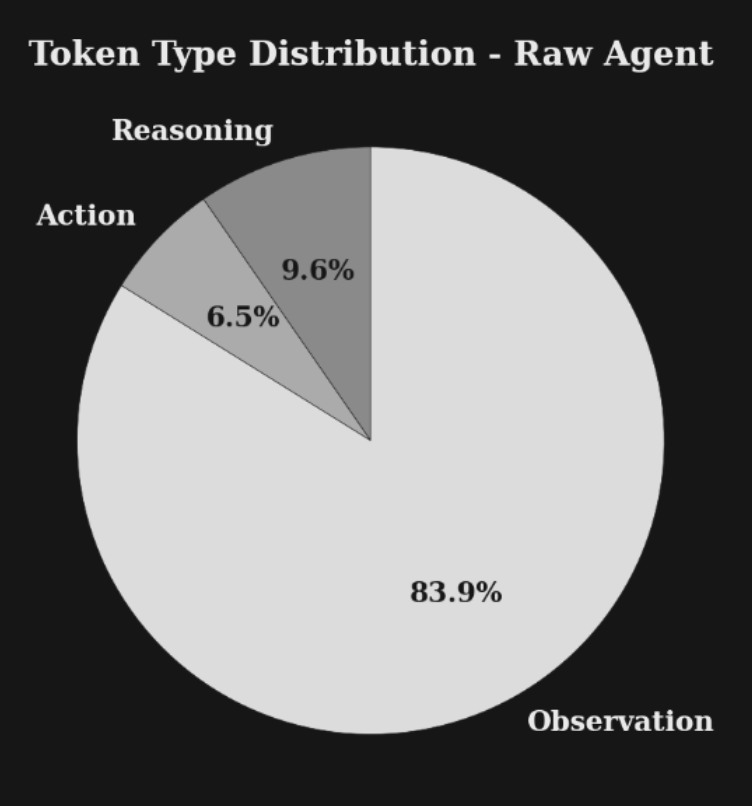
This presents a problem - how do we 'preserve' the relevant context from the tasks completed so far, while freeing up enough context to keep progressing through the todo list?
Most tools today solve the problem by 'compacting' the existing context, either automatically or manually, which 'summarizes' the conversation so far, and replaces the past 'raw' history with this summary [1]. While this does allow the LLM to continue working without completely forgetting the past, the effectiveness of this versus other approaches is unclear. While 'summarizing the conversation' intuitively makes sense, is it strictly necessary?

Just Delete Context?
It turns out, if we just remove the past tool-call results (e.g. observations) from the context window, in 'observation heavy' agent trajectories, we can achieve equal or better results to an "LLM Summarization" approach without the additional summarization token cost. This non-intuitive result, highlighted by the paper "The Complexity Trap: Simple Observation Masking Is as Efficient as LLM Summarization for Agent Context Management", was demonstrated on Gemini 2.5 Flash and Qwen 3 (480B Coder and 32B variants) with similar outcomes, for both thinking and non-thinking configurations. Figure 3 illustrates the concept - in the second column, 'observation masking', old observations are replaced with a fixed "mask" (e.g. 'Previous X lines elided for brevity'). This is essentially deleting old observations - not even preserving a short 'summary' of their contents.
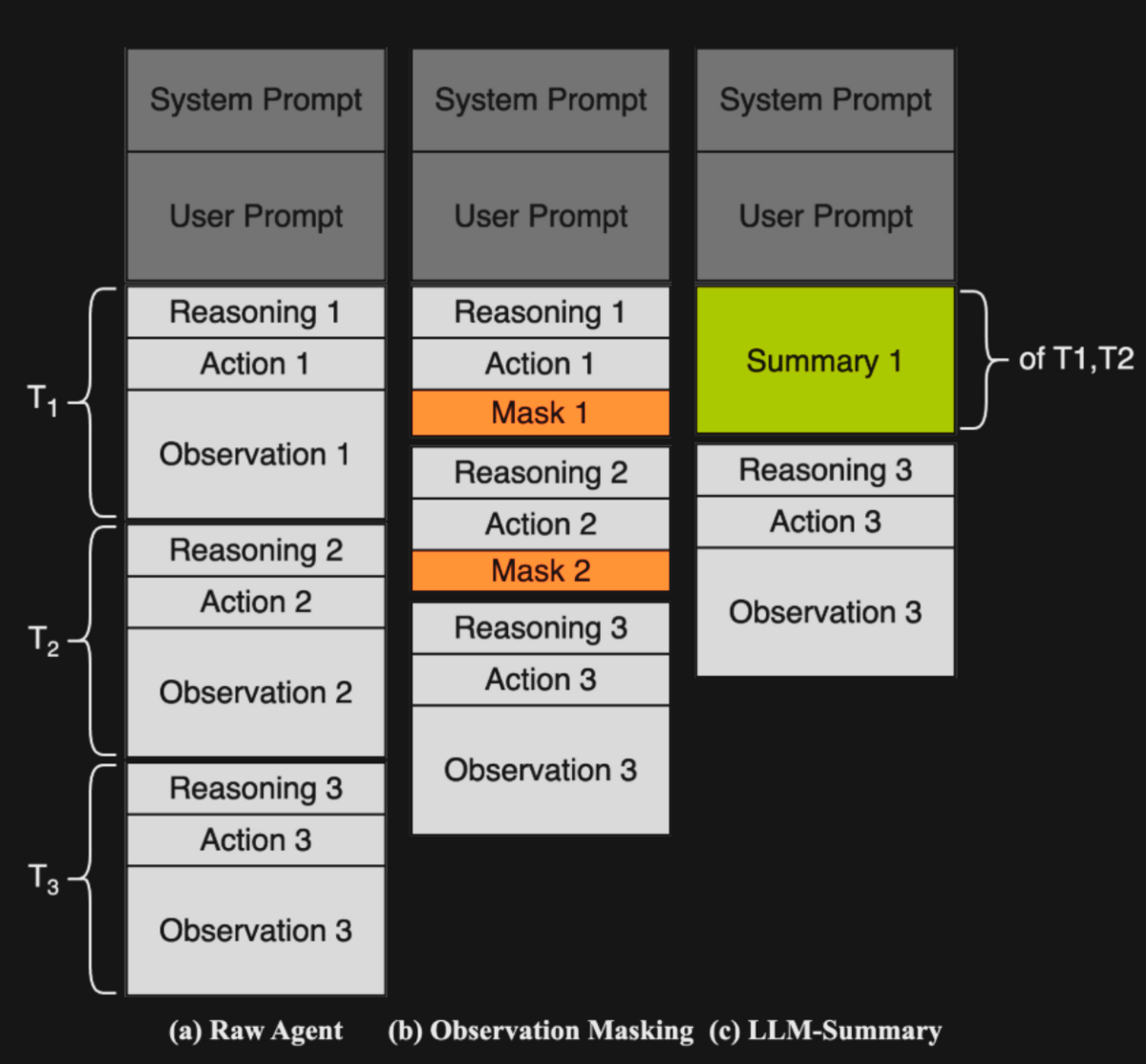
Their tests used SWE-Agent on SWE-Agent-Verified as a scaffold, and found that for 4 of the 5 models under test, Observation Masking outperformed the 'raw agent' approach, and came very close to LLM Summarization (exceeding it in some cases).

This strongly implies that 'too much' context can harm results, even if the model 'can handle it' in the context window. In other words, an agent might do better at certain tasks by forgetting context thats not directly helping it achieve the remaining tasks in its trajectory.
"Our analysis uncovers a fundamental insight: LLM-based summarization can inadvertently encourage “trajectory elongation,” where agents persist on unproductive paths, an effect especially pronounced with powerful models like Gemini 2.5 Flash or Qwen3-Coder 480B. Moreover, summary-generation LLM calls account for a nontrivial fraction of per-instance cost for the strongest models (5–7%), eroding the net efficiency of these approaches."
"The Complexity Trap" Authors
Understanding the reality that 'more is not always better' helps us build better agentic systems, by what is effectively test-time data curation. As the authors note, there is likely some middle ground here between 'deleting context' and 'existing summarization strategies'. They explore this in section 5, by trying to introduce a "Critic" model that examines the agent trajectory so far, and generate reflections on the agents actions so far instead of summarizing context. Figures 12 and 13 capture this, excerpted here:
But, another surprise: even the joint critic approach underperformed 'observation masking'. Sometimes, simpler is better.
More Reading/Watching
LangChain has an extensive, very readable article on Context Engineering covering pitfalls of large context windows (conflicting context), types of context, isolating context, and managing context across various domains.
The founder of HumanLayer also put together a helpful talk called "Advanced Context Engineering for Agents" advocating for 'spec first' development when working with agents.




