

Agentic Systems are Loops
Giving a model tools is the first step towards an 'agentic system'. At this point, you're likely familiar with the basic 'agentic tool loop' - give a model a goal, give it tools, and let it use those tools to attempt to achieve the goal. Want the weather? Give a tool-calling model access to a weather API, and now it handles requests like "What's the weather in <Location> on <date>?" by calling tools and synthesizing the results until it reaches a 'reasonable answer' (or the loop hits a termination condition).
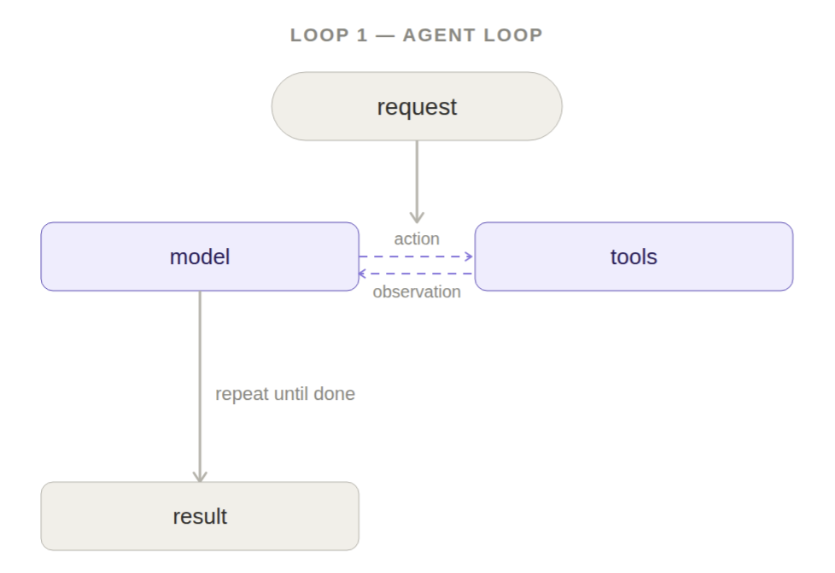
Claude Code (possibly the most well-known agentic coding harness) defines the core agentic loop as "gather context, take action, verify results", with the ability for a human to 'interrupt' and adapt the loop to changing needs. Claude Code is ~98% harness, with permissions logic, custom plugins, subagents, session persistence, and a slew of other features. But fundamentally, the model is still looping through 'gathers information', 'takes action' (tool calls), and 'verify results':

The 'interruption' (lower left block) to add context or steer the loop doesn't need to be a human-initiated event - it could be a webhook, a cron job, another agent finishing a task, or in the case of the Langchain "Docs Agent", a Slack message:
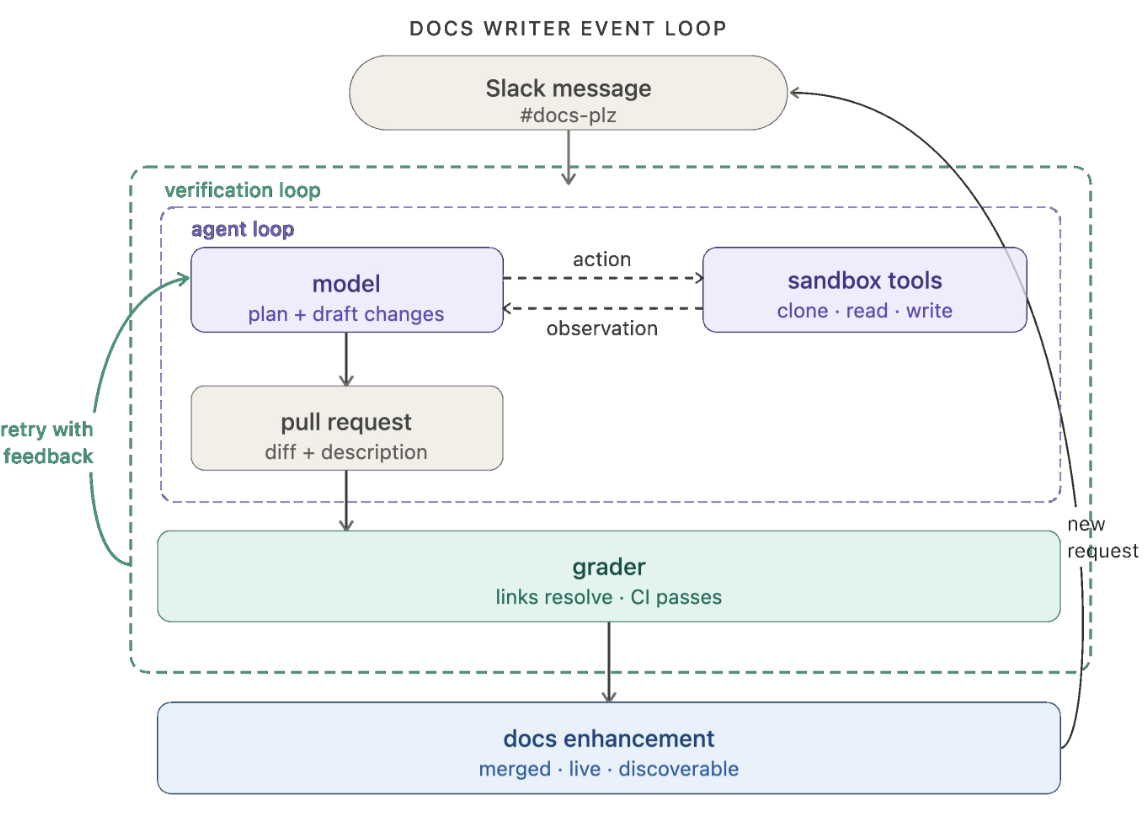
A clear pattern emerges: a signal initiates an agent loop, the agent uses tools to do work within that loop, and the resulting work is graded or verified. For example, in the Docs Writer scenario above, it deterministically checks, "Do all links in the generated doc resolve to a real URL?" This leads to either a retry with feedback ('fix the links') or a finished work product.
These same primitives (hooks, tool-use loops, feedback from a judge/grader, finalization) generalize across multi-agent architectures. They can be arbitrarily nested and composed, enabling inner feedback loops:
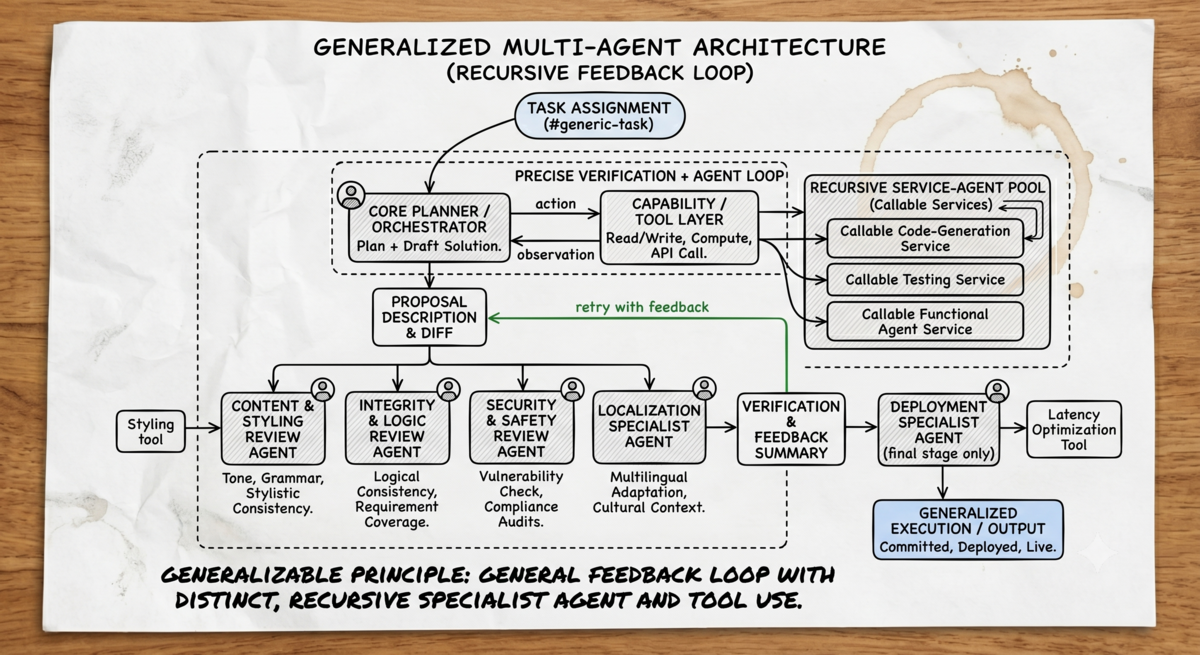
Building these loops well enables useful long-running agents, because the feedback and verification cycles (if designed properly) keep the output 'on the rails'. Put simply, if you can give the model domain-specific tools that verify what 'good' looks like, you enable the agent to do 'good' work. An effective harness aligns system output with user intent. But as the harness develops, questions emerge:
- Do you add another agent, or add to the system prompt of an existing one?
- If we change the format of the verification result, will the feedback to the planner agent improve or worsen?
- Do you add more context to step A, or add a new step?
- When do you reset the context, and do you use a sliding window or summarization for in-context history?
- When do you decide you need to formalize an action as a deterministic tool-call?
- When do you use agents sequentially, versus allowing an orchestrator agent to call other agents 'as tools'?
- Is it worth adding more inner-feedback loops?
(For a great real-world case study on 'long-running agent harness development' today, take a break here and read "Harness Development for Long Running Apps" from Anthropic).
The typical answer (and still a critically important one) is implementing end-to-end evals, which provide a signal on the quality, efficiency, latency, and almost anything else you can measure qualitatively or quantitatively about an agentic workflow. Make a change to the harness, run the eval, compare the results, and repeat - if the eval is designed well, improving the eval score improves the result.
Often, however, the harness itself is not easily composable, consisting of unique handlers, side effects, and ad-hoc context management. What formalization would allow us to automatically improve these harnesses?
Enter HarnessX
HarnessX formally defines an agent as a 'processor pipeline bound to a model, both independently substitutable'. Model substitution makes sense (swap in a different model string), but to accomplish harness substitution, they defined a harness configuration as a 'typed, substitutable entity' which consists of a hook-indexed list of processors, and a fixed set of slot resources (which are shared global resources across all processor instances, such as a sandbox provider, tool registry, or plugin list).
A 'processor' is a strongly typed async function that receives an event as input, and emits zero or more events. This allows a processor to ignore an event, pass it through unmodified, transform and re-emit the event, fan the event out to multiple other processors, yield nothing, or raise an exception (e.g. an interrupt). Processors can be swapped in and out interchangeably; as we'll see, this is a key 'design decision' that enables automatic optimization of a harness in HarnessX.

So now we've got a model selected, a set of 'slot resources', a list of tools, and processors on various hooks that 'do something' with event data. We use this configuration to perform a task, and generate traces. Normally, this is where human intervention occurs, to monitor task trajectories and manually improve the harness.
AEGIS
In HarnessX, the "AEGIS evolution loop" allows automatic improvement of a harness. It starts by framing the harness configuration as state, the traces from executing a task in that harness (plus verifier scores over the result) as feedback, and typed edits of the processor(s) within the harness as actions. This is intentional, as it frames harness improvement in the same way we think of reinforcement learning - then applies a similar iterative approach to improve the harness as we would to improve a model.
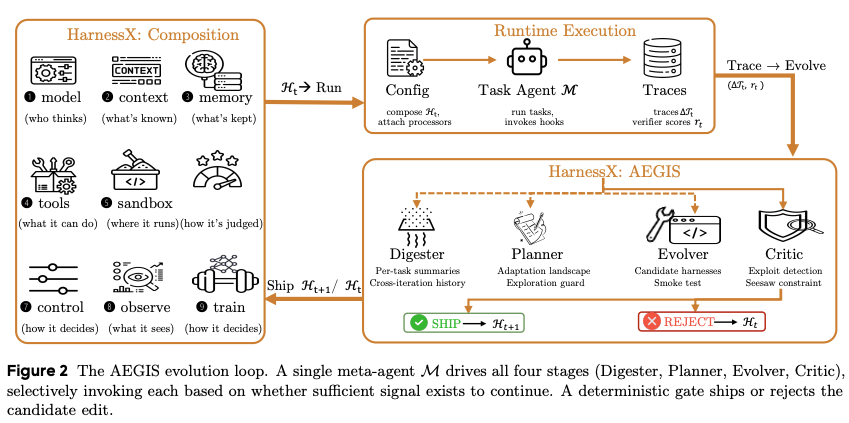
By looking at traces from a run of the harness, AEGIS decides whether to modify the harness to improve performance, and how to do so. It starts with a "Digester" step which compresses the raw traces into task-level insights, and only proceeds to the "Planner" phase if any failures or interesting behavior occurs (if nothing is found to improve upon, AEGIS exits early).
This same 'fail fast' philosophy applies to the downstream stages - any stage can exit early if it does not believe there is a path forward to harness improvement. If the Planner phase identifies a way to adjust the harness that could solve the observed failures, it proposes those to the Evolver phase, which attempts to generate specific, type-safe edits to the harness to implement the plan. The Evolver provides the proposed harness edits, and specific tasks it expects this change to improve or regress.
Finally, the Critic phase either approves the result from the Evolver (and ships an updated harness), or loops back to the Evolver with feedback (at most once), or exits with a failure. The Critic is also responsible for considering whether the change is net positive, or if one task gets better while others get worse (a seesaw constraint).
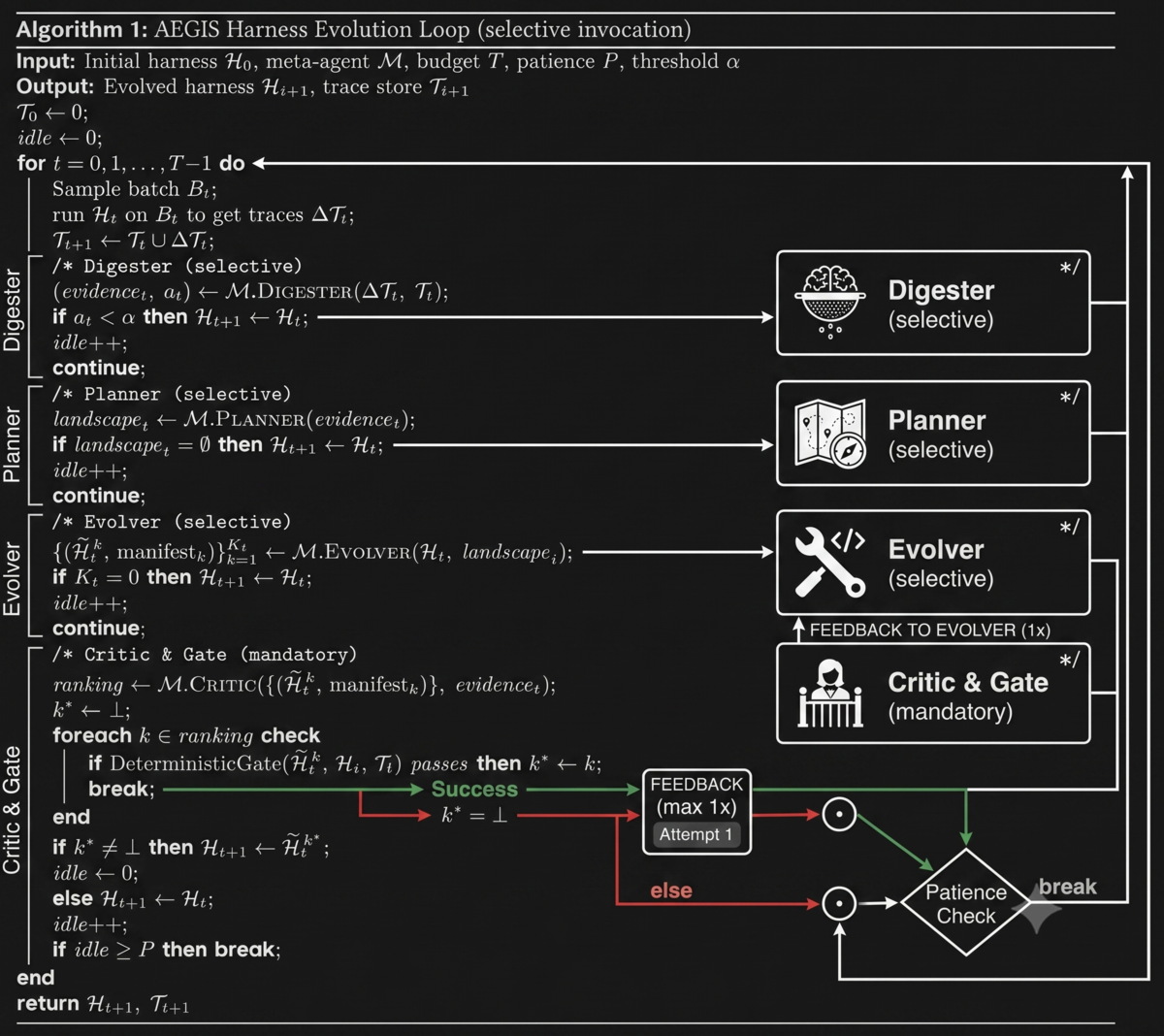
Once a new harness configuration is generated, it's guaranteed to be executable (due to the type safe interchangeable nature of the processors defined by HarnessX), so re-running on the new harness is a trivial operation. We don't cover it here, but the HarnessX paper also goes over co-evolving the underlying model alongside the harness.
HarnessX Results
It depends on the task, but take WebShop as an example:
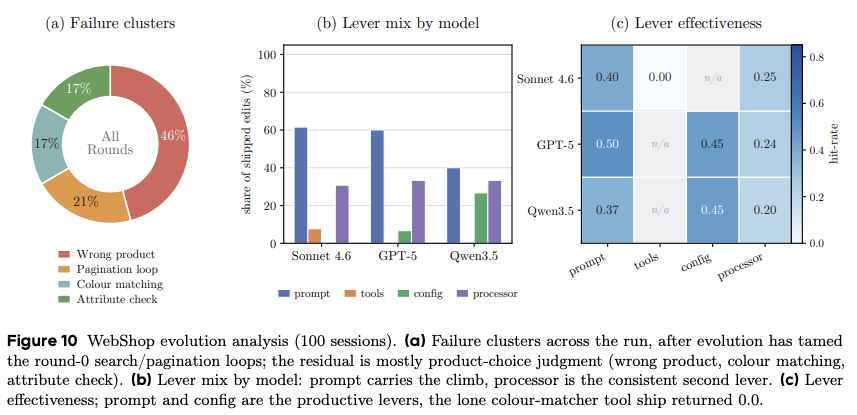
WebShop measures how well an agent can use a retail site, including searching for a desired item, selecting the right item, and purchasing it. Notice that across frontier-adjacent models (Sonnet 4.6 and GPT-5), prompts dominate the effective 'evolved harness' changes, tool changes are almost nonexistent on all models, and configuration makes up more of the changes on Qwen than on the frontier-adjacent models. Interestingly, the 'effectiveness' of config changes remained about the same across GPT-5 and Qwen 3.5, whereas GPT-5 had much bigger impacts from prompt changes than Qwen 3.5 on the same task.
Note that the paper also describes a co-evolution approach to improve a weak model alongside the harness, but if you're using strong models already (GPT 5, Sonnet 4.6, Kimi 2.5, etc) improving the orchestrator model is unlikely to improve agent performance as much as improving the harness. As the HarnessX authors put it:
"For a capability-limited small model, harness evolution eventually meets a scaffolding ceiling: once the harness exposes the right tools, context, and control flow, the binding constraint becomes whether the frozen model can actually exploit them, and no harness edit can supply reasoning capacity the model itself lacks."
Stronger Models or Better Harnesses?
If a coding agent fails to refactor a codebase, it’s rarely because the model doesn't know JavaScript syntax; it’s because the harness failed to parse the test logs correctly, didn't chunk the context window properly, or let the model get stuck in an infinite loop. The solution is rarely 'train a new model' in these cases. Even with 'auto-evolving' harness approaches like AEGIS, improvement relies on good evals and deterministic validators, which give automatic improvement techniques a goal to measure against.
New harness engineering approaches will continue to emerge, and the upshot for AI engineers is that we are currently at the discovery phase of finding the 'right' harness primitives to improve model performance for a given task, as we move beyond the era of static, one-off agent loops.
While HarnessX is experimental, LangSmith Engine and PostHog Code are tools available today to help close the loop between 'eval signal' and 'improved agent harnesses'. Expect to see more in the second half of 2026.


