

What is a Specification?
A specification defines what a system should do, and why, strictly decoupling intent from the how of implementation. Specifications are not constrained to 'plain English'; consider that formal methods provide mathematically verifiable specifications, but are difficult to communicate to non-technical stakeholders.
But there is no rule that says we have to pick one language or technique 'per specification' to express intent. We can combine executable diagrams, formal proofs, written functional/nonfunctional requirements, and pass/fail evaluation cases. If all of these exist, the specification is potentially more expressive than the implementation code itself.
Sean Grove (OpenAI) defines a specification as "One artifact, three roles: communicate intent, adjudicate compliance, and evolve safely", which introduces a temporal dimension - specs should have a mechanism to stay aligned with and ahead of the system design.
As AI models dramatically accelerate the speed at which concepts translate into code, a 'spec-first' approach to development is becoming feasible. As the team at Galileo notes, this shift changes the fundamental atomic unit of software creation, and in a sense it feels like waterfall. Whether starting from requirements, or deriving requirements from existing design constraints, the spec-driven approach attempts to 'shift left', defining system behaviors upstream of the code implementing those behaviors.
Tools like Github's Spec-Kit and Kiro are two examples of developer-facing interfaces for the 'spec first' paradigm (see Birgitta Böckeler's Understanding Spec-Driven Development for a deep dive into those tools). What they have in common is the idea that the specifications should provide grounding for what needs to be built, and agentic harnesses that read these specifications should have mechanisms to verify that the code actually 'meets spec'. At a high level, this often takes the form of a generated task list grounded in the specification, which, when completed, should ensure the code 'implements' the specification.
Böckeler suggests there are at least three 'levels' of spec-driven development, depending on the longevity of the specification itself, and where the weight of the system definition lives. In a spec-driven flow, the 'source of truth' for how the system operates shifts into the specification, and 'source code' becomes more akin to 'artifact code'.
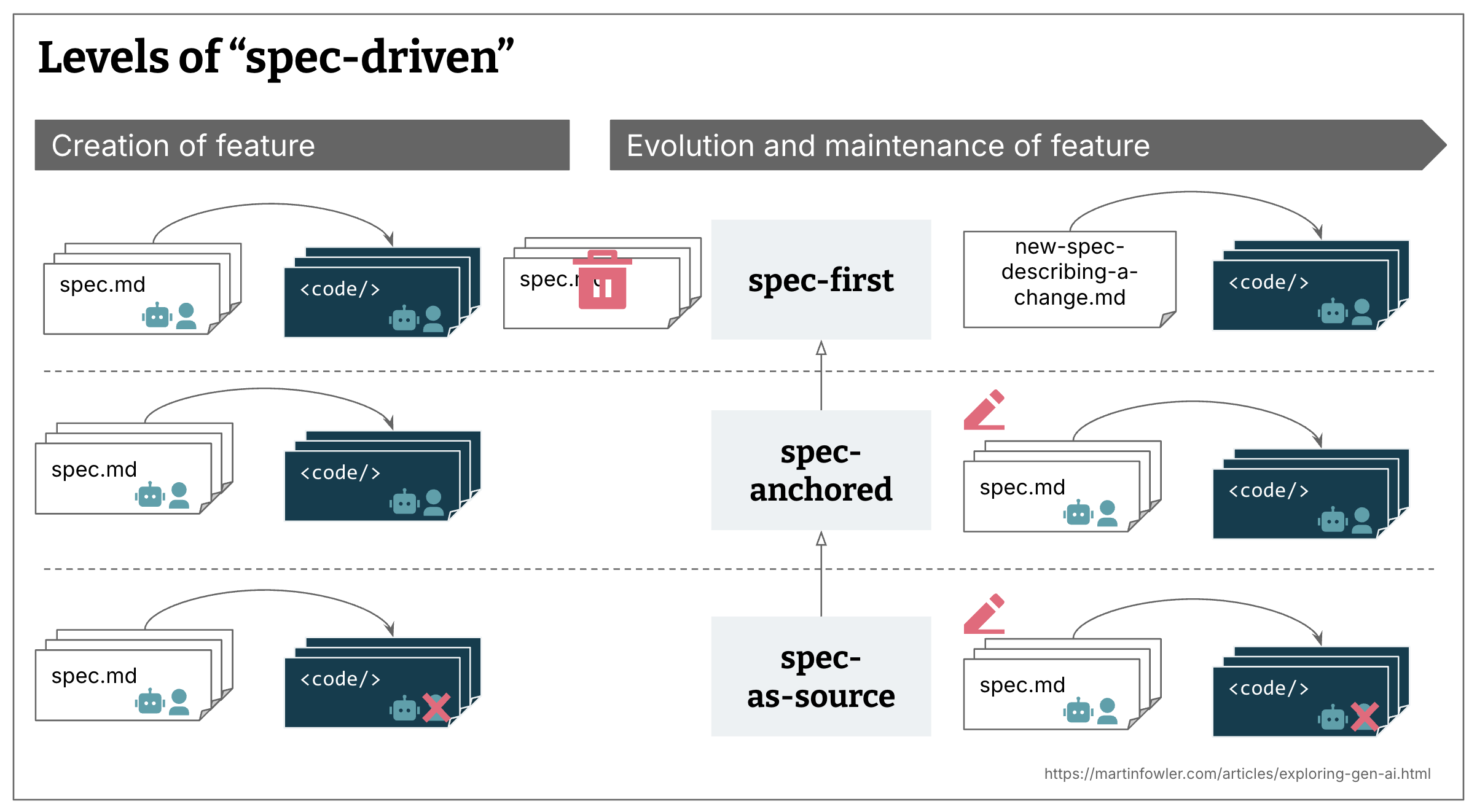
Why not Code?
But, isn't code already a specification? And if so, why the emphasis on a separate specification at all?

If a specification is just pseudocode with some English mixed in, it becomes an implementation detail. For example, if a 'spec' defines gRPC protobufs, database schemas, or Typescript interfaces, perhaps it is too 'in the weeds' to provide meaningful value compared to source code, as it is still just dictating syntax and mechanics.
On the other hand, consider a distributed system interfacing multiple services and clients across platforms and languages. Before touching code, what if we defined what outcomes we care about, or more concretely, functional and nonfunctional requirements (FRs/NFRs). What if we could reason about the architecture and invariants of that system at a higher level, thinking in terms of constraints:
- Any user account balance must never drop below zero
- The auth token must expire within 15 minutes
- The order status endpoint must respond in under 250ms at the 99th percentile, even during peak load.
- Peak load is 10k requests per minute
Since AI models excel at authoring the how (e.g. 'writing/implementing code'), a specification provides differential value by strictly defining the what and why of the system. Instead of telling the LLM "write this exact migration", we're defining a goal (codified by the NFRs/FRs), without unnecessarily limiting how the model gets there. Importantly, the 'what' here also provides 'success criteria' for an agentic development workflow, where 'done' is not reached until all of the 'what' conditions (FRs/NFRs) are met.
Importantly, if our specification captures all the aspects we care about, we allow an agent to optimize across unexpected dimensions in the implementation. For example, maybe the agent executes some performance tests when exploring ways to achieve our peak load response time requirement, and finds that an event-sourced architecture would let us meet the requirement and opts for that approach. We don't define the technical solution itself; we define the end goal, and treat the implementation as an iterative process of discovering a solution that meets our requirements.
"This sounds like No-Code..."
The core promise of no-code platforms like Bubble was to 'democratize' app creation to creators who were not developers. And for some use cases, it worked well. But the fundamental constraint of no-code has always been its affordances, which were necessarily more limiting than just writing code.
When you build in a traditional no-code tool, you are restricted to the primitives the vendor has designed for you. If you need a standard CRUD application with basic user authentication, the visual blocks are there. But the moment your application requires logic slightly outside the platform's visual 'vocabulary', like a complex distributed transaction or a specific background job, you'll hit a hard ceiling of capability.
Spec-first agentic development flips this dynamic entirely. By treating code as a generated, auditable artifact, the expressiveness of the 'spec' is limited only by the language of the spec itself (e.g. a combination of English descriptions, state machines, or formal specifications like TLA+), the combination of which might be even more expressive than code written in a single programming language.
In a sense, no-code still exists as a separate 'parallel' path to spec-first development. The 'no-code primitives' that the vendor provides are a 'spec', just in a language constrained by the primitives of the no-code platform.
Constraining Specifications via a "Constitution"
Of course, just because a specification exists does not mean the system will be 'better' than simply prompting it into existence. Garbage-in, garbage-out still applies. If we treat agents as autonomous co-developers, the specification is their management layer. We don't hand a junior developer a two-sentence Jira ticket and say 'push to prod once its ready', so its not clear why we do the equivalent with ambiguously prompted coding agents. Spec-driven development is just applying standard engineering management to non-human actors.
When Anthropic introduced 'Constitutional alignment', they demonstrated that models can recognize and 'self-align' against a set of guidelines (a 'constitution'). Today, you can read the full "Claude Constitution", which is a specification of a sort, with the goal that all other training and guidance for Claude remains consistent with that document.
'Constitution as a grounding document' is also core to the Github spec-kit approach, which includes an interactive flow to create a project constitution as one of the first steps, which then 'guides' subsequent spec creation.
The recent Constitutional Spec Driven Development paper applies this concept specific to the security domain. By focusing a constitution around CWE mappings, strict enforcement levels (MUST/SHOULD/MAY), and providing compliance traceability (file and line number granularity mapping) results in over 70% reductions in security vulnerabilities. This is worth exploring, because the approach is domain agnostic.
In Section 3.4, they discuss the architecture - notably, there are feedforward signals (the constitution and the spec), and feedback (the compliance traceability, as well as a 'validator' ) - it is not a 'one-way' street from the spec to the code.
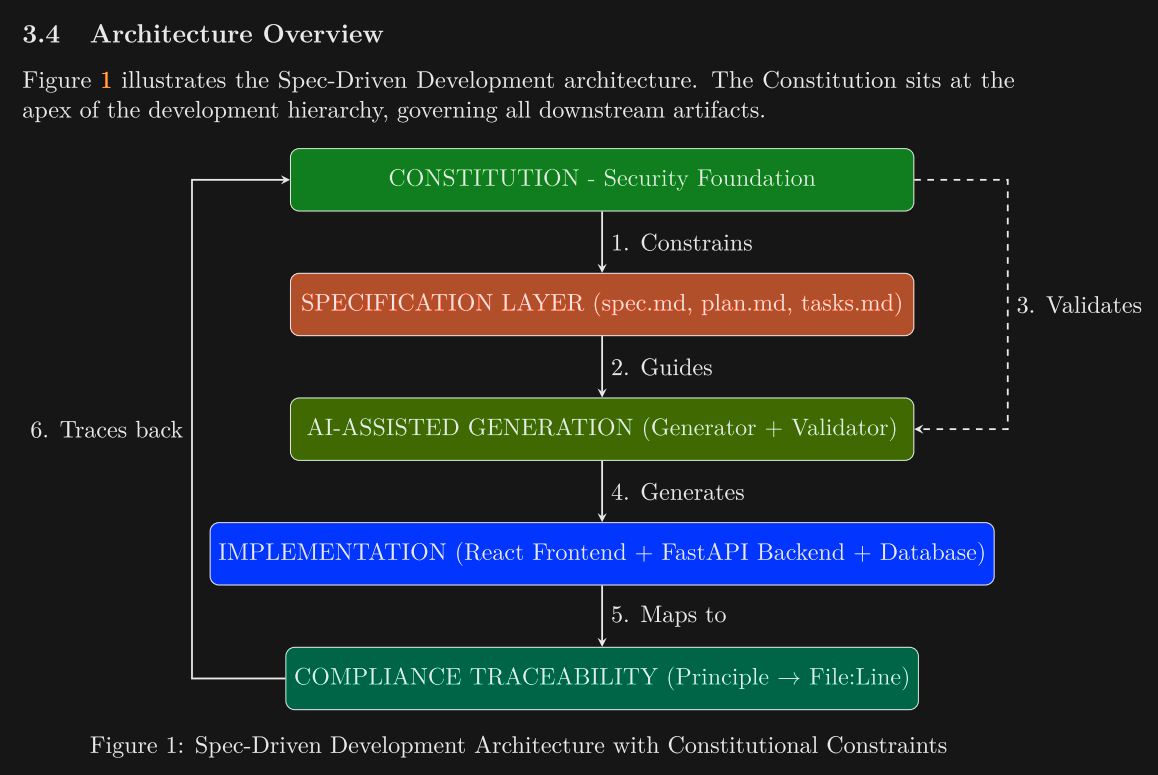
The 'constitution' consists of structured statements that specify an ID, a CWE reference, enforcement level, constraint, implementation pattern, and rationale, as seen below:

Rather than just dropping these principles in the context window and hoping for the best, the authors run a 'validation' step after any code generation, which reviews the proposed code against these principles. This is essentially a 'feedback' loop that drives the agent to identify non-compliant code, and self-correct it:
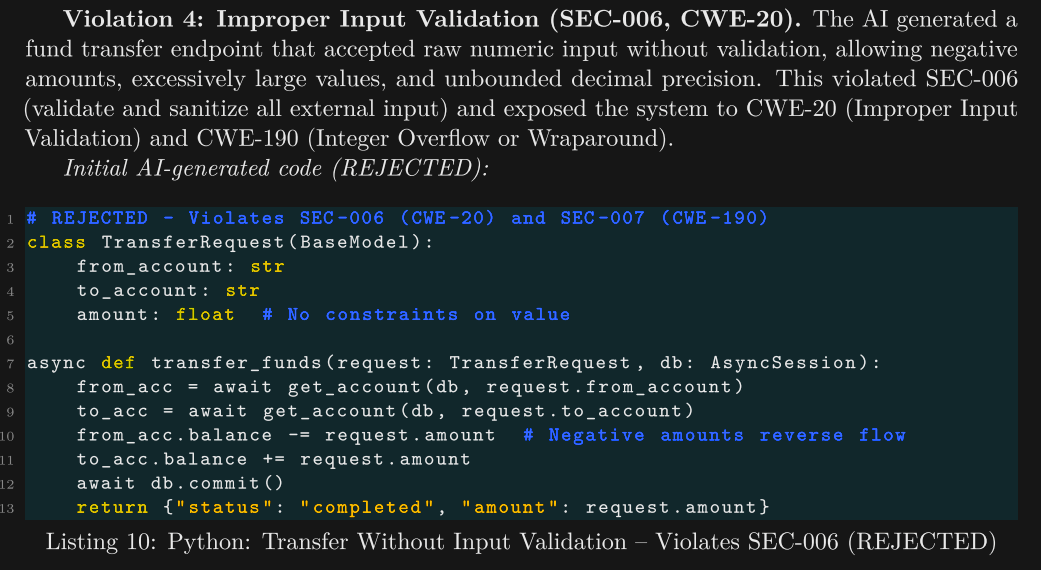
After the code rejection, the agent moves on to correct the issue by using Pydantic typing of the input parameters (numeric range constraints for the amount, and regex matching for 'valid' account strings), and hardens the transfer_funds function to block wraparound/reverse account flow.
Notably, using the same developer, same coding agent (Claude), and same end goal, the paper compares development with and without this constitution-driven alignment. Simply by making the requirements explicit up front, and providing both feed-forward (constitution drives specs, which drive code generation) and feedback ('verification' phase) loops, they cut the CWE violations of the generated code by almost 4x, cut the time to a secure build in half, and improved compliance documentation from 23% to 100%:
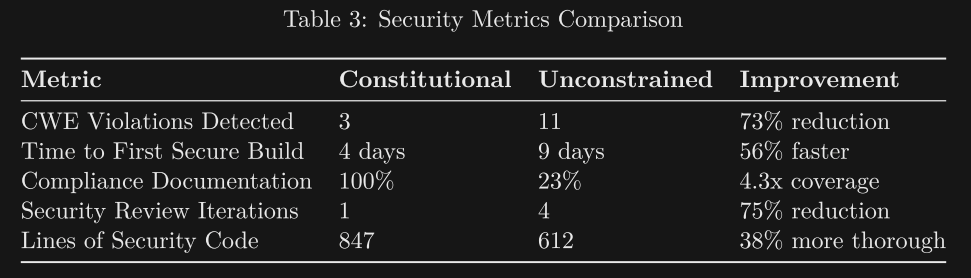
Spending time up front codifying what matters to your team reduces churn and subsequent review, getting generated code to a trusted state sooner. Maybe the decision is not between 'vibe code' and production code, but the discipline to define what matters to your team, so that the agents generating the code prioritize what matters, not just 'what works'.
Bonus: The "Kitchen Loop" UAT Verification Approach
So, we've got a constitution, some specs, and code generated from them. Greptile, Codex Review, and our custom Kimi 2.6 review agent are telling us the code matches the spec, and our constitutional invariants are preserved. Unit tests exist, and they are passing, yet when a new user tries to send a magic link to sign in, we see a Sentry error. What's going on?
On the one hand, maybe we failed to specify that workflow well enough. But what if the spec-to-implementation itself is untrustworthy?
The Kitchen Loop provides a few ways to address this, and builds on top of specifications. Its requirements are (from section 17.3 in the linked paper):
- An enumerable specification surface - What the product claims to do
- An automatable test environment - Can an AI agent exercise the product?
- A regression oracle - Can you answer 'is the system still working' in bounded time?
- The discipline to run it continuously - and trust the output when the tests are unbeatable
To achieve 'unbeatable' tests, Kitchen Loop requires any agent implementing code to create a "Test Card", which defines how a human user would manually test the feature. It cannot contain implementation code, it cannot reference internal unit tests, and it must include at least one "bad input" to ensure the system gracefully rejects invalid states. If the test card cannot be written, that is a signal to push the feature back upstream to better specify it - to avoid incomplete implementations from landing.
Once ready, the test card is handed off to an entirely separate, weaker model (like Claude 3 Haiku) spun up in a clean, zero-context environment. This evaluator agent isn't allowed to edit code; it simply reads the card and attempts to execute the steps as a blind user in a fresh worktree.

If this sounds like end-to-end testing, that's because it is. But it is E2E testing that is fully automated, dynamically generated from the spec, and executed by an adversarial agent with no ability to change the underlying code.
Note: I occasionally chat with and advise engineering teams who are hitting a wall trying to get their LLM workflows out of the prototype phase and into safe, reliable production. If your team is wrestling with agentic code churn or architecture scaling, feel free to ping on LinkedIn or X at @jmilburn_


