

Spatial Intelligence
The concept of 'embodied intelligence' (or embodied cognition) is an emerging trend at the intersection of AI, robotics, and cognitive science, with funded labs working towards "World Models" that can accomplish meaningful tasks in the real, physical world.
Human intelligence has many facets. One is verbal intelligence, enabling us to communicate and connect with others through language. But perhaps more fundamental is spatial intelligence, allowing us to understand and interact with the world around us. Spatial intelligence also helps us create, and bring forth pictures in our mind's eye into the physical world. We use it to reason, move, and invent - to visualize and architect anything from humble sandcastles to towering cities.
One aspect of "Spatial Intelligence" is the concept of spatial memory, which we'll explore here by walking through the 3DLLM-Mem paper from UCLA and Google Research.
Memory: Working vs. Episodic
The 3DLLM-Mem work relies on the concepts of 'working' vs 'episodic' memory, so lets introduce a basic definition of these terms. Working memory is like your brain's temporary workspace, holding and manipulating a small amount of information actively in your conscious awareness for immediate tasks, such as remembering a phone number while dialing it or keeping track of the steps in a recipe you're currently following. In contrast, episodic memory stores your personal experiences and events from your past, like remembering your first day at a new job or what you had for dinner last Tuesday. While working memory has severely limited capacity and duration (typically holding 4-7 items for seconds to minutes), episodic memory can store vast amounts of autobiographical information indefinitely.
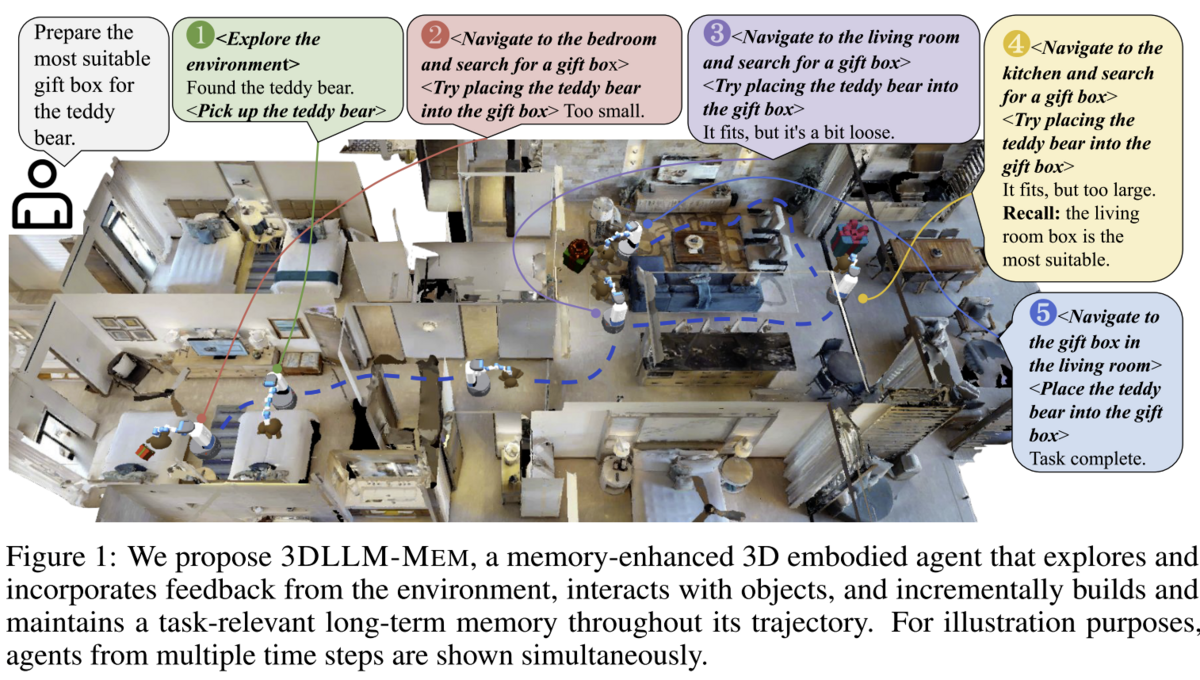
This distinction matters when trying to introduce spatial awareness to an agentic system which is tasked with performing 'real world' actions, where object permanence and location context ('pots and pans are in the kitchen') are concepts which matter to task completion, but can't realistically all be kept in the 'foreground' (context window) 100% of the time. Figure 1 of the paper (excerpted below) gives an example task that requires temporal and spatial reasoning - finding the 'best' gift box for a teddy bear.
3DMEM-Bench
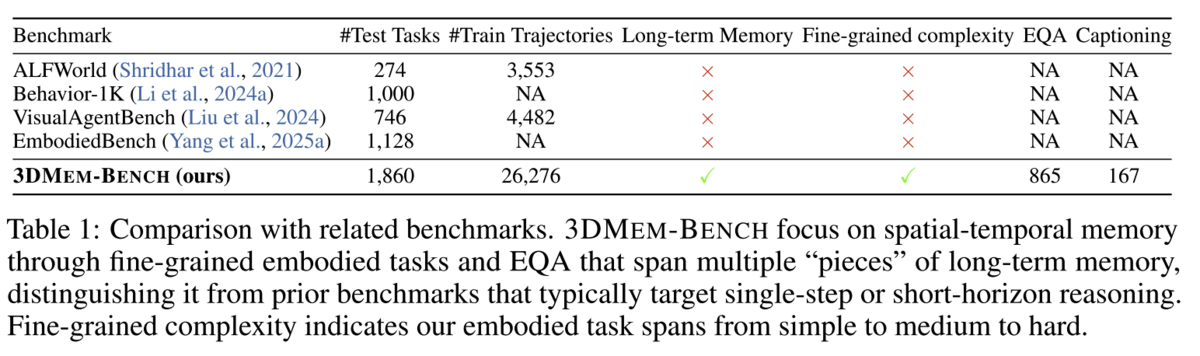
Before jumping into 'solutions', the paper authors developed a benchmark that indicates whether an embodied agent is reasoning effectively over long-term memory in 3D environments (specifically, multi-room environments from the Habitat dataset, augmented with 'interactive' objects that an agent can manipulate). They classify tasks in difficulty gradations from 'simple' to 'hard', with complexities varying from 'collect these objects' to tasks that require properly sequencing actions across time and locations. Compared to previous benchmarks, 3DMEM-Bench adds long-term memory and fine-grained complexity, allowing for embodied QA (EQA) task evaluation with spatial-temporal evaluations. For an example of an existing EQA dataset that does not take into account temporal considerations (e.g. 'What color is the car in this scene?'), check out https://embodiedqa.org/
The main difference between 3DMEM-Bench and prior benchmarks is the definition of tasks that require the embodied agent to maintain and utilize long-term memory intelligently through a series of chained actions. This is the difference between "Find and move the laptop from the bedroom to the kitchen" and "Remember where I placed the laptop yesterday, and make sure it ends up in the same place once you're done serving breakfast tomorrow morning, before I start work".
Figure 2 from the paper (excerpted below) gives an idea of the specific long-term memory EQA evaluation categories (object counting, spatial relation, room layout, comparative, and object navigation) as well as the captioning capability that the benchmark evaluates. Notice the temporal elements that this eval introduces ("Which carpet has larger area now", "How many ceiling lamps are there after the task finished?", etc).

To create meaningful dataset tasks, the authors pass bounding box information about a multi-room environment, as well as bounding box information about objects in each room, and ask the LLM to generate task trajectories for the benchmark.

The system message used is from Appendix E (copied for reference above), but the appendix is a treasure trove of useful prompt ideas for embodied agent work. Within the task trajectory prompt itself, they include considerations like:
- Limiting the agent to holding one object at a time
- Ensuring objects used by the task are placed in a diversity of rooms
- Limiting valid actions to a specific set of action tokens (e.g. "GO TO ROOM", "PICK UP", "PUT DOWN", etc),
- Attempts to force the task to require long term memory (e.g. "Ensure the agent must remember something seen long ago rather than simply following an explicit list"
- Including explicit reasoning in the task trajectory to explain possibly ambiguous 'correct' decisions (e.g. selecting table(1) vs table(0) based on reasoning around the correct sized table for a given task)

Once a task trajectory is created, the authors use another prompt to generate "QA" for steps along the task trajectory, by providing the trajectory executed so far, the input scene information for the current agent position (e.g. bounding boxes, RGB-D data), and in-context examples. This is the source of the "Long-term Memory EQA" questions which evaluate an agent's performance on a given task.
3DLLM-Mem
After developing 3DLLM-Bench to keep themselves honest on how well their embodied agent performed tasks requiring spatial and temporal reasoning, the team went on to build 3DLLM-Mem to accomplish those tasks.
They start with an embodied agent, capable of observing the space around it, moving, and picking up or putting down objects. The team based their model on LLaVA-3D (which provides basic 3D spatial awareness out-of-the-box), and extended it by introducing 'fused episodic memory' and 'working memory'. Working memory for the agent consists of 3D Image patch tokens (spatial data about the scene the agent is currently observing) at a certain moment in time. As the agent moves to another environment (e.g. a new room), the agents working memory goes into the episodic memory, and if that environment is already present, it is updated with the latest observations from working memory.
To implement 'fused' memory, the 3D features from working memory are encoded into a shared memory space which can be used to query the episodic memory, and 'similar' memories are pulled into that shared memory space, which is the 'fused' memory referred to in Figure 3 below:
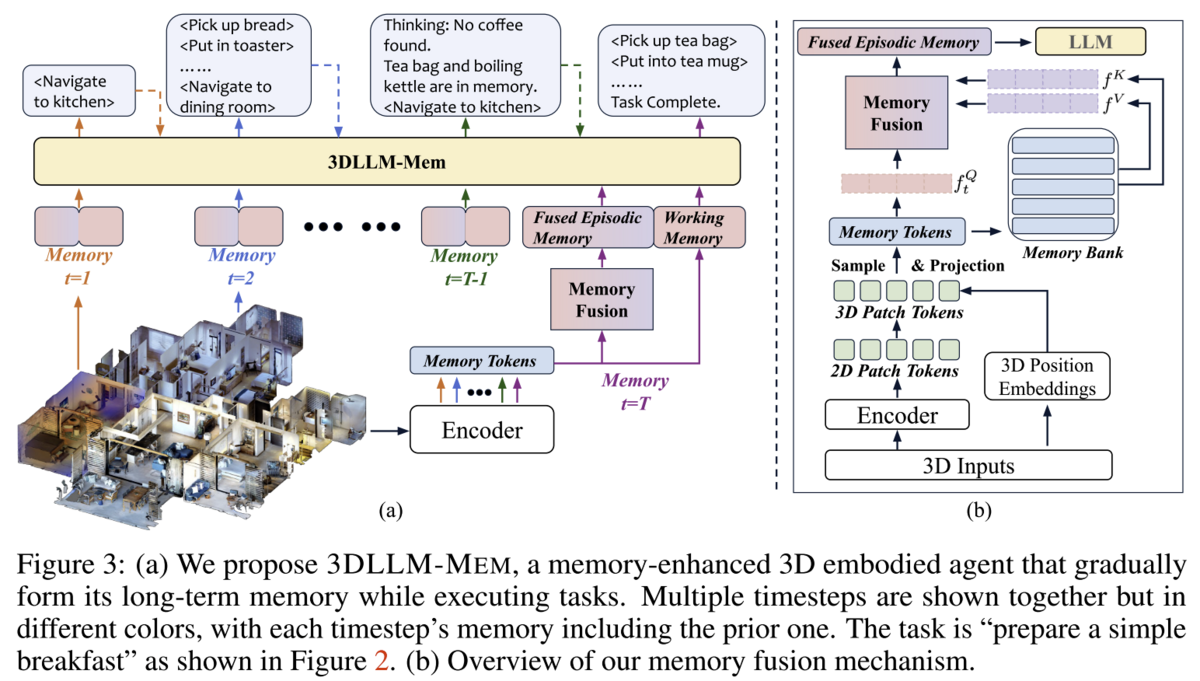
The researchers compared 3DLLM-Mem to other approaches, including "Everything in Context" - and 3DLLM-Mem outperforms the 'everything in context' model, further emphasizing on the idea that 'large context windows aren't a panacea'.
Experimental results demonstrate 3DLLM-MEM significantly outperforms all existing approaches in both in-domain and in-the-wild embodied tasks. Notably, while the performance of other methods drops sharply in the challenging in-the-wild setting, our method remains robust, achieving an average success rate of 32.1%—demonstrating strong generalization capabilities.
3DLLM-Mem paper
Takeaways
Often, thinking clearly about the problem space, spending time building good benchmarks to evaluate performance in it, and then moving to implementation can yield an elegant, high performance solution. In the 3DLLM work, after developing a useful, domain-specific benchmark (3DLLM-Bench) the authors don't 'build a 3D model from scratch', but instead fine-tune LlaVA-3D on Google TPUs in less than a day, and end up with a spatially aware agent that can build a "cozy reading nook". What can you do with a similar approach?



