
Personalization in Generative AI
Personalization within consumer facing agents is widespread, whether implemented as a project level abstraction, passive background monitoring via desktop screenshots, or aggregated information from other apps on the same platform as the inference service. Typically, conversational turns in the chat interface are monitored for possible 'preferences', such as 'the user enjoys randonneuring', and these observations are collected and organized into a summarized context for that user.
For a concrete example, consider the "Peer Card" that Honcho memory framework (used by Hermes Agent) creates for each 'peer' in the system (where peers can be agents, humans, or any other communicating entity):

Personalization and long-term memory are worth distinguishing from Retrieval-Augmented Generation (RAG). RAG is a catch-all term for any inference that uses 'retrieved' information (which could be from any source, not only vector stores).
Mem0 digs into this difference in their "RAG vs Memory" post, and define a 'good memory layer' as one that:
- Extracts data from the conversation in realtime that describes the user, and places it in a memory store
- Periodically prunes 'stale' data about the user, and both creates new memories and updates old ones
- Provides a way to retrieve data on a 'per-user' basis
But, so far, the focus is about describing the user - and not about (directly) operationally changing how an agent performs tasks on behalf of that user.
Personalized Decision Policies
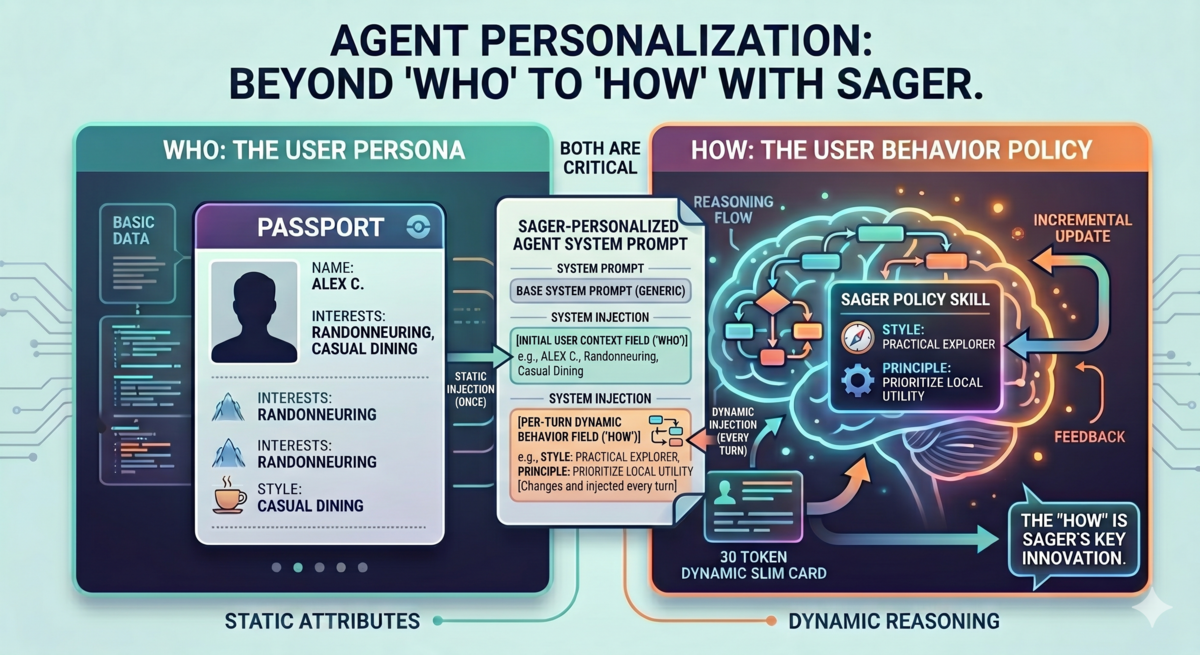
In SAGER ("Self-Evolving User Policy Skills for Recommendation Agent"), the authors recognize that most personalization today focuses on 'who' a user is and 'what' they prefer or don't, but the 'how' doesn't change, and focus on how to change the way agents reason on a per-user basis. That 'how' is defined as a policy, or the section of the system prompt containing 'decision principles', instructing the model on the way to approach problems and questions from the user.
Figure 1 from the paper illustrates the point:
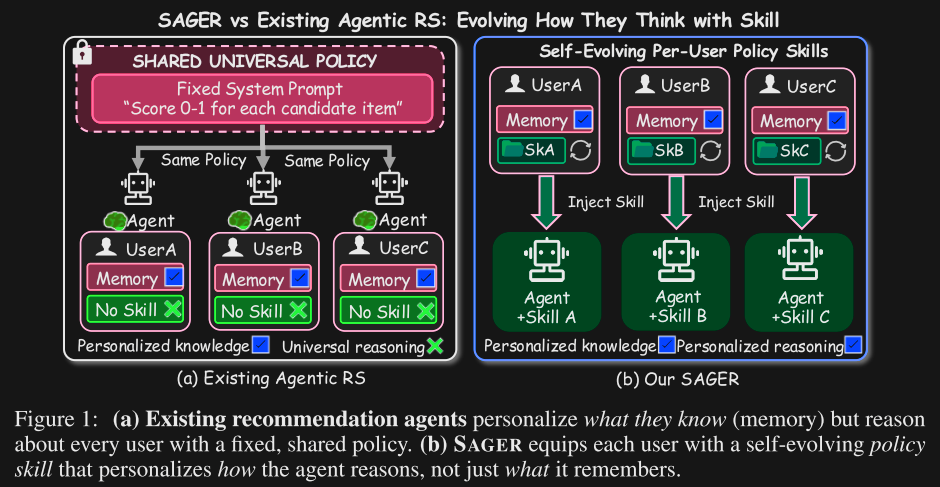
The per-user 'agent skills' in Figure 1b capture the way that user thinks and wants the agent to make decisions - not just information about their persona. Building these policies requires overcoming the Injection Paradox, where 'richer information' in the prompt should improve model performance to a point, while staying below the threshold where too much context dilutes the models ability to focus on the user's query.
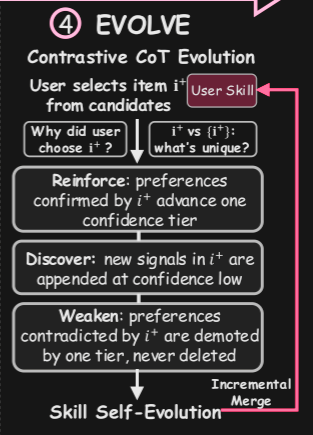
SAGER addresses this through what they call an "incremental contrastive chain-of-thought engine", where policy updates happen through structured diffs, created by reasoning over the contrast between choices that a user selected versus those they rejected or ignored. Based on this difference, SAGER then reinforces or weakens existing decision policy rules, or discovers new rules. This is step 4 in Figure 2 from the paper:
The resulting 'policy skill' is surprisingly succinct - in the SAGER approach, the goal is ~30 tokens, resulting in per-user injected policy skills as simple as:
- Likes: casual dining, local cafes
- Style: practical neighborhood explorer
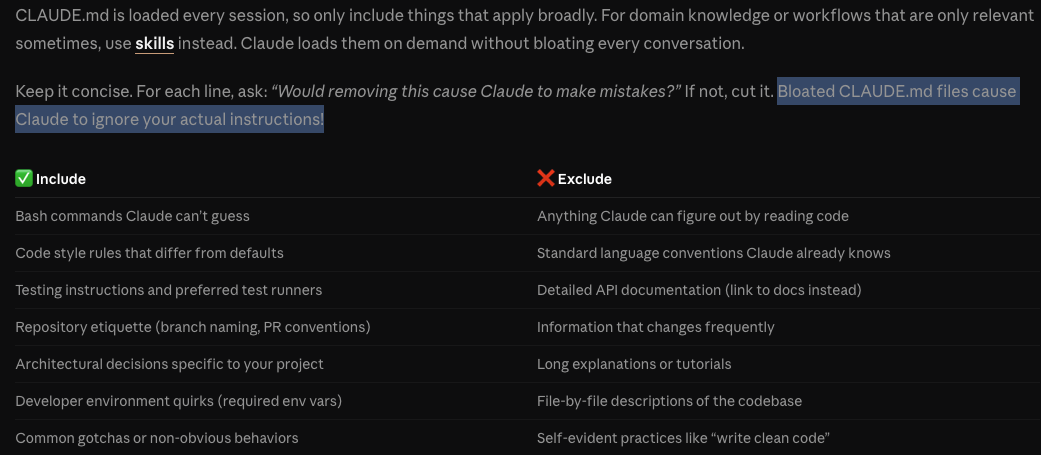
The 30 token limit is based on their tests with gpt-4o-mini, which found 30 tokens as the Pareto-optimal point, beyond that, the instructions had significantly less influence on the actual model behavior. This mirrors general 'best practices' in the industry around 'instruction context' (see Anthropic's CLAUDE.md guidance below), but the 30 token limit may seem surprisingly low, given gpt-4o-mini has an 128k length input context window.
However, as seen in the brief 'dining' example earlier, 30 tokens doesn't give much room for information - so SAGER stores a larger, ~1500 token per-user policy skill in memory, and uses this as the main reference. When it is necessary to inject user policy into a system prompt, they dynamically derive a 'slim working skill' (~30 tokens) that includes 1-2 likes, and one dominant style, both relevant to the specific task at hand. In this way, they're able to selectively inject the most important context, rather than dumping 1500 tokens and hoping the agent picks up on the 'right' details for the current user request.
Performance
So, how does SAGER compare to existing approaches for user recommendation? It turns out, quite well. On GoodReads and Books datasets (as well as Yelp and MovieTV), the SAGER approach outperformed 'traditional' recommenders, LLM-based recomenders with and without memory, and a fairly recent LLM-based collaborative recommendation approach from earlier this year (MemRec):
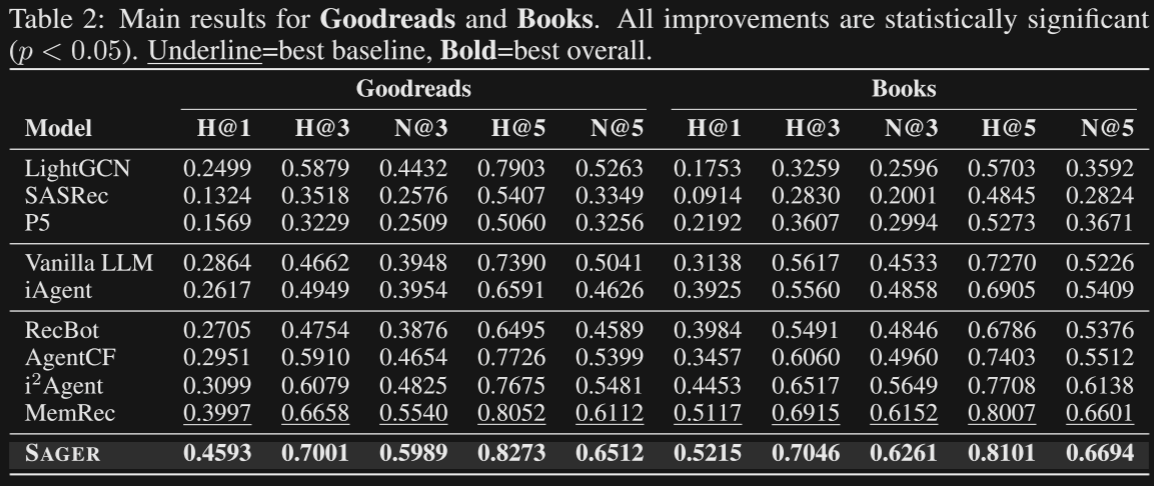
H@M indicates "hit rate", and means "out of M recommendations, one of the M recommendations was the book the user actually purchased ". So an H@1 of 0.4593 means "~46% of the time, SAGER with one 'top' recommendation picked the book the user ended up purchasing", and H@5 of 0.8273 means "~83% of the time, when SAGER recommended 5 books for the user, one of those 5 was the one the user actually ended up purchasing".
N@M is short for "Normalized Discounted Cumulative Gain" (NDCG), which is a refinement of hit rate. Basically, NDCG is hit rate with the addition of including ordered 'ranking' in the score. In other words, if a recommendation engine suggests books A, B, and C, and the user's preference was Book A, that specific recommendation order (A, B, C) will get a higher score than putting A later in the list (e.g. recommending C, B, A will score lower than recommending A, B, C).
The fact that SAGER scores higher in both metrics indicates that the approach of evolving an understanding of 'how' a user thinks, not just 'what' they think, can improve the ability of LLMs to take actions on behalf of a user (in this case, 'purchasing a book they'd like').
Recommendation engines represent only a small slice of the capability of autonomous agents today, but demonstrating that teaching agents 'how' to make decisions can improve alignment with user goals - which has implications across other long-trajectory tasks.
Usage in Agents
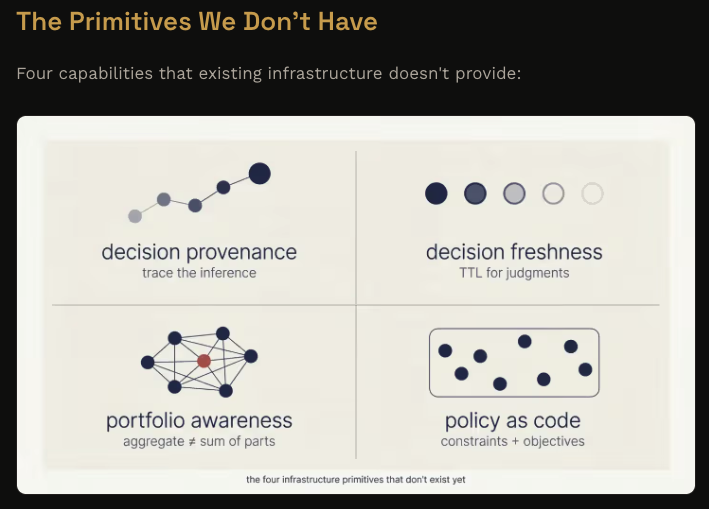
AgentField identifies 'policy as code' as one of four missing primitives for a world where software makes non-deterministic judgments at runtime, describing these as 'auditable, versionable' rules that can be reasoned about formally.
The need for these formal rules becomes more evident as teams start to adopt practices like spec-driven development and delegate entire roles to digital teammates ala gstack. When long-running agents are given more autonomy, ensuring their alignment does not drift as they proceed to complete a task is critical. For example, Moonshot recently reported that Kimi 2.6 demonstrated a 12+ hour continuous execution period with over 4,000 tool calls that led to a useful result (~20% faster local inference than LM Studio). When an agent is running autonomously for half a day, a static 'write efficient and safe code' isn't enough to keep it on track.
This is exactly where the evolution of memory comes into play. While frameworks like Honcho give agents like Hermes the critical context of who you are, SAGER’s approach represents the necessary next step: injecting how you think. By evolving auditable, bite-sized decision policies, we can ensure that as agents take on longer-trajectory tasks, they are making choices grounded, on a turn-by-turn basis, in actual team policies and preferences.


