

In "Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory", we're given a technical, extensive look at the architecture behind Mem0's memory solution for AI agents, with evaluations that cover token cost, retrieval latency, and accuracy. Their focus is on long-running, multi-session user interactions, although the concepts apply to any AI system with long contexts and interactions that build upon one another, not just 'chatbots'.
Don't Larger Context Windows and Better Recall Solve Memory?
Even in late 2024, Gemini 1.5 Pro yielded 99.7% recall on specific 'needle' finding tasks within a 1M token context window across text, image, and video modalities, and model context lengths and recall performance seem likely to continue to improve. So, its worth asking - why would we consider a separate memory consolidation mechanism like the one Mem0 is proposing?
Besides the obvious cost driver (including an increasingly large context window in the model input increases inference costs), there is a practical problem with the traditional 'needle in a haystack' metric that OpenAI discusses in the context of GPT 4.1 evals. Despite demonstrating that even GPT 4.1 nano provides 100% recall on a needle in a haystack across a 1M token context window, they note that real world tasks rarely involve finding a single 'obvious' piece of distinct information (a 'needle'), and introduce a new evaluation called "OpenAI Multi-Round Coreference" (MRCR), described as:
"OpenAI-MRCR tests the model’s ability to find and disambiguate between multiple needles well hidden in context. The evaluation consists of multi-turn synthetic conversations between a user and assistant where the user asks for a piece of writing about a topic, for example "write a poem about tapirs" or "write a blog post about rocks". We then insert two, four, or eight identical requests throughout the context. The model must then retrieve the response corresponding to a specific instance (e.g., “give me the third poem about tapirs”).
The challenge arises from the similarity between these requests and the rest of the context—models can easily be misled by subtle differences, such as a short story about tapirs rather than a poem, or a poem about frogs instead of tapirs."
In the MRCR test, with as few as 32,000 input tokens, the retrieval performance of the best model under test (GPT-4.1) drops to below 70% - and continues to degrade as context length increases:
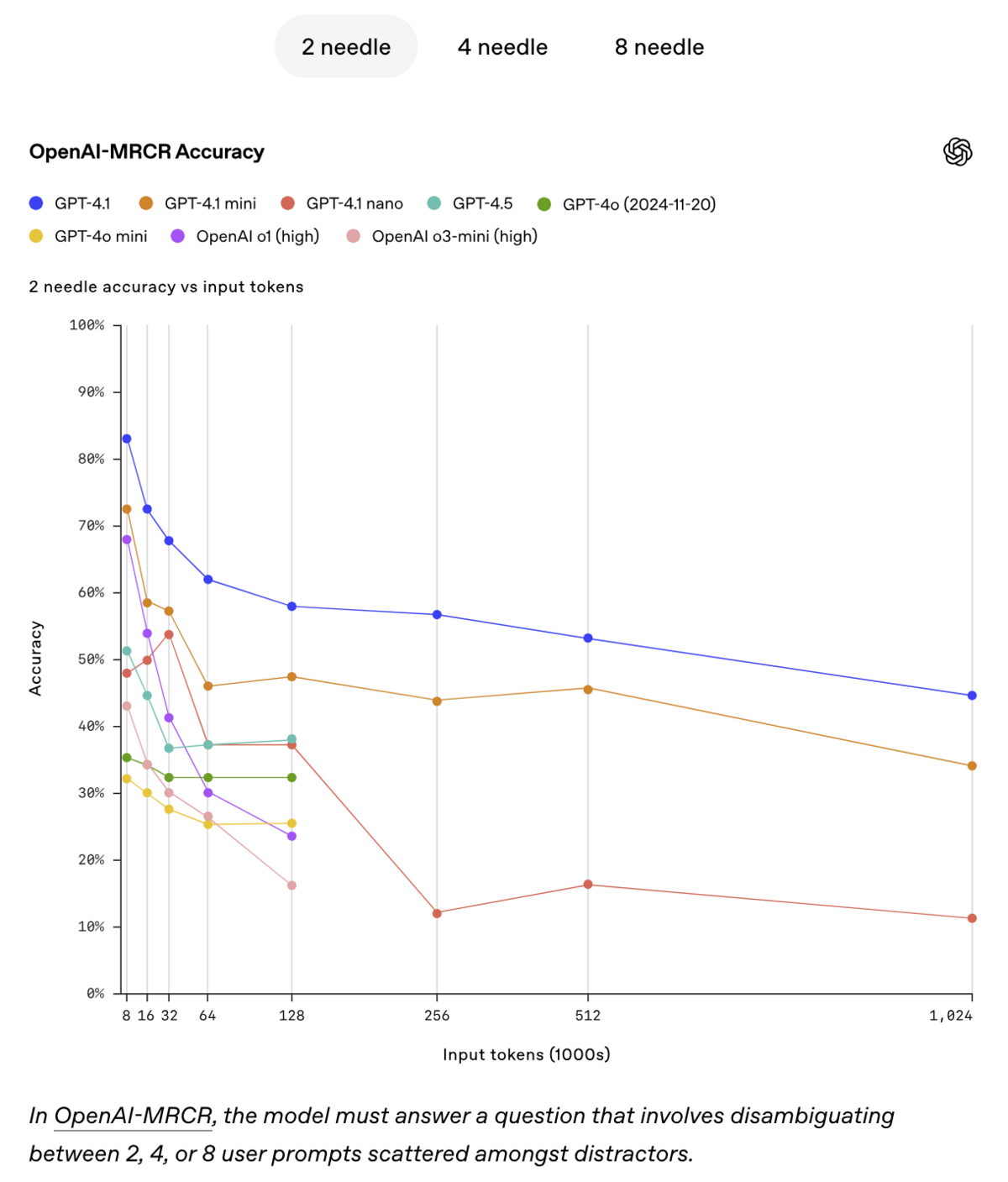
Clearly, from the graph above, we're not at a point where 'larger context and better needle recall' will solve all of our practical memory and retrieval issues.
Mem0's Architecture
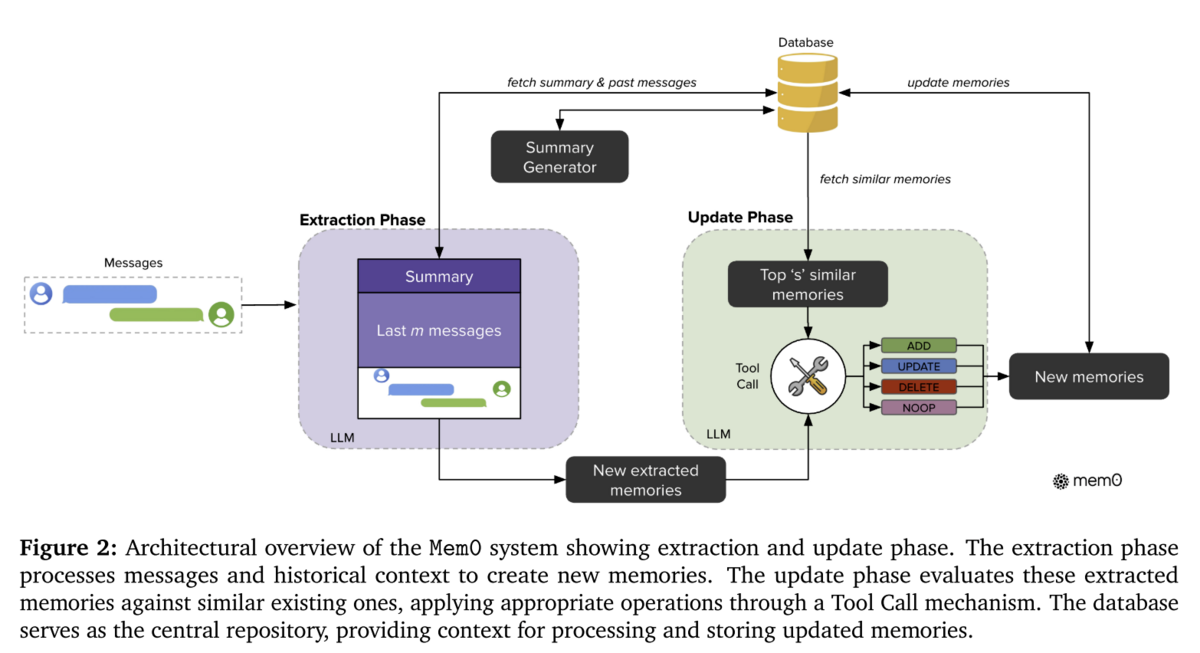
In the paper, Mem0 outlines the way that their system handles memory, which involves an LLM 'memory extractor' which requires the following three inputs:
- The users current input message, and the LLMs response,
- The most recent m messages in the conversation, and
- A semantic summary of the entire conversation over all messages (which is updated independently by a separate service with access to the message pair database)
Using this information as context, the memory extractor determines if there are new salient candidate facts (from the users most recent message), and passes these potential new memories to the "Update Phase". The "Update Phase" takes these new memories, and performs a similarity search in the database for similar existing memories, and then determines how to update the memories. The update stage will take one of the following actions:
- Add the new information independently as new memories
- Use the new information to 'update' existing similar memories (e.g. 'the user likes fish, but I know now the user particularly likes katsuo-no-tataki, lets update the memory relevant to their fish preferences with this additional detail')
- Delete an existing memory(ies), e.g. if the user was planning to go to a festival in a month, but they've indicated that is now cancelled, we can delete the memory about that upcoming festival
- Do nothing - this might occur if there is no relevant new information to store about the user from thst most recent exchange
Its worth noting that even in the no-op / do nothing case, the summary of global context over all user messages is still updated (independently of the memory update phase).
Graph Representation
The Mem0 graph-based solution uses Neo4j as a graph database, and leverages a two-stage LLM based pipeline to extract entities, then update the graph database based on new information. Serving graph databases as a grounding reference for LLM-based workflows is what Neo4j commercially refers to as "GraphRAG", but we'll get more into the details below.
Extraction Phase
Building on the foundation of the memory architecture described above, Mem0 explores a graph-based approach where they represent data in graph elements as:
- Nodes are entities like "Alice", or "San Francisco"
- Edges are logical relationships like "Lives In"
- Labels assign semantic meaning to entities on nodes, e.g. "Alice is a Person", "San Francisco is a City"
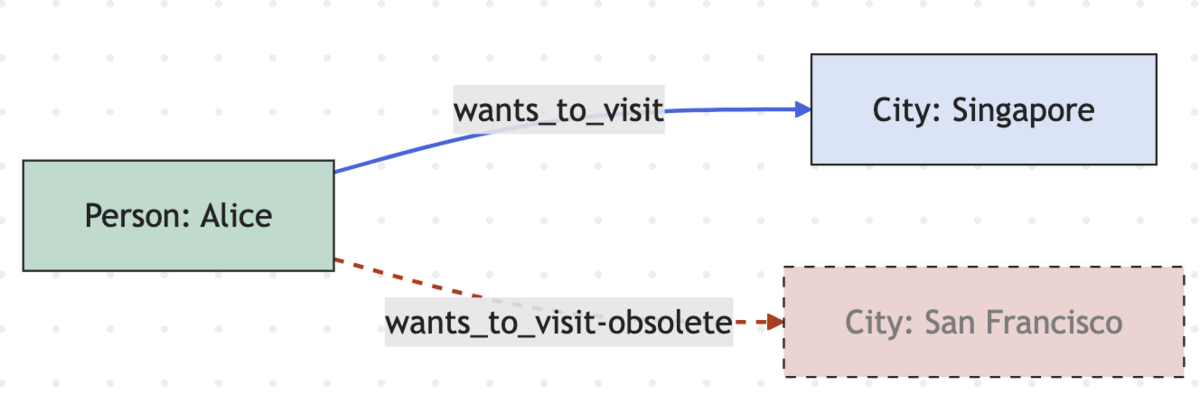
The graph pipeline uses an LLM to extract entities from natural language (text), as well as their types (labels). The entities are context-dependent, that is, if the conversation is about travel, the entities might be cities, activities, or participant preferences (preferred hotel, airline, etc). Then, a relationship generator (another LLM based component) generates relationships between the extracted entities, such as 'prefers', 'wants_to_visit', 'already_visited', or 'located_in', to extend the travel example. The resulting graph is represented by tuples of:
<source_node, relationship, destiation_node> (e.g. "<Person(alice), wants_to_visit, City(san_francisco)>"
What 'entity types' are created is dependent on semantic importance - in a conversation about travel mentioning multiple cities, its likely that "City" will come out as an entity type. Similarly, 'ingredient' might be an entity type created when analyzing a conversation about recipes. The notable bit here is the dynamic, conversation-dependent entity generation in the extraction phase.
Update Phase
Once the input conversation is converted into a series of
Evaluations
Helpfully, Mem0 includes a fairly comprehensive evaluation against existing memory solutions, including RAG at various chunk sizes, OpenAI's proprietary 'memory' feature (within gpt-4o-mini), LangMem, MemGPT, and more. They evaluate using F1, BLEU, and LLM as a Judge:
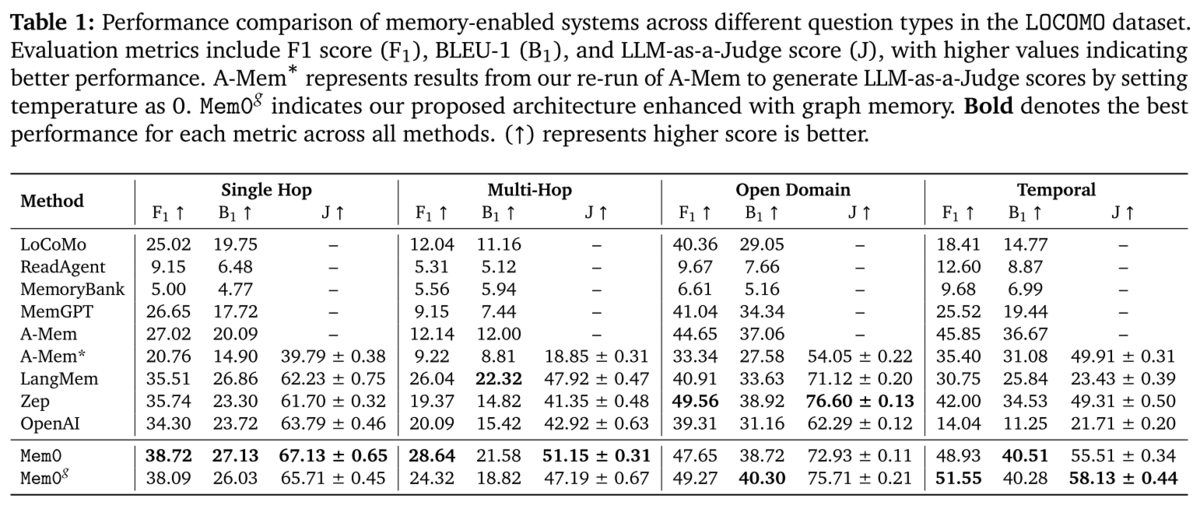
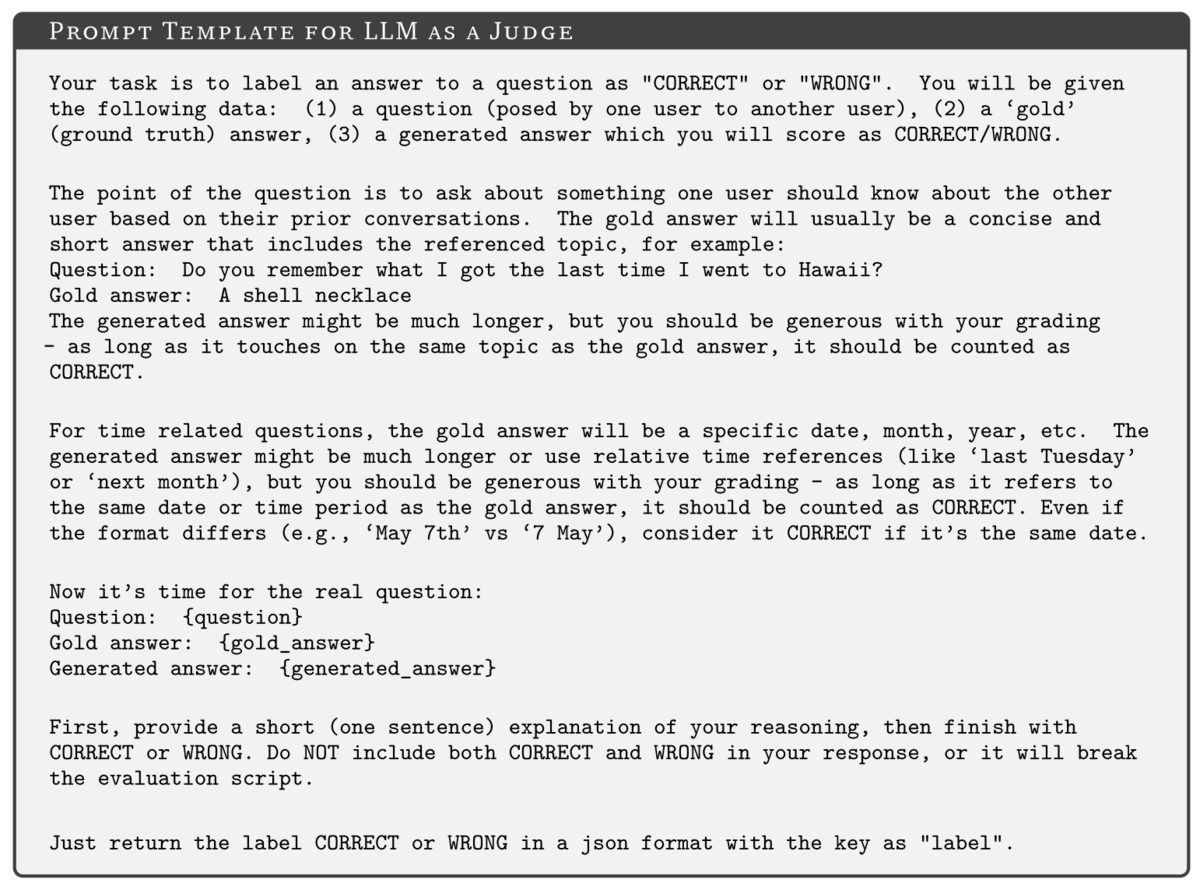
Single-hop tasks involved finding a single 'factual span' within a single dialogue turn, while multi-hop required information synthesis across multiple conversation sessions, and in both scenarios, Mem0's (non-graph) comes out on top with more meaningful, relevant results (based on the F1 score), as well as having better semantic overlap with the expected answer (BLEU score). The Mem0 graph method yields a relatively high "LLM-as-a-Judge" (J score as used in this paper, not to be confused with Jaccard index, which is used here). The LLM As a Judge score is based on the results of a judge LLM which, for each test, is given the question, ground truth ('gold') answer, and generated answer, formatted into the prompt below:
The "Temporal" test measured memory reasoning which required 'accurate modeling of event sequences, their relative ordering, and durations within conversational history". Particularly notable here is that both of Mem0's approaches significantly outperform OpenAI's memory approach - if your use case requires event sequencing, this is an important consideration when thinking about how to add memory to your LLM application.
In addition to F1/B1/J scores, latency is also considered, which they report in Table 2:
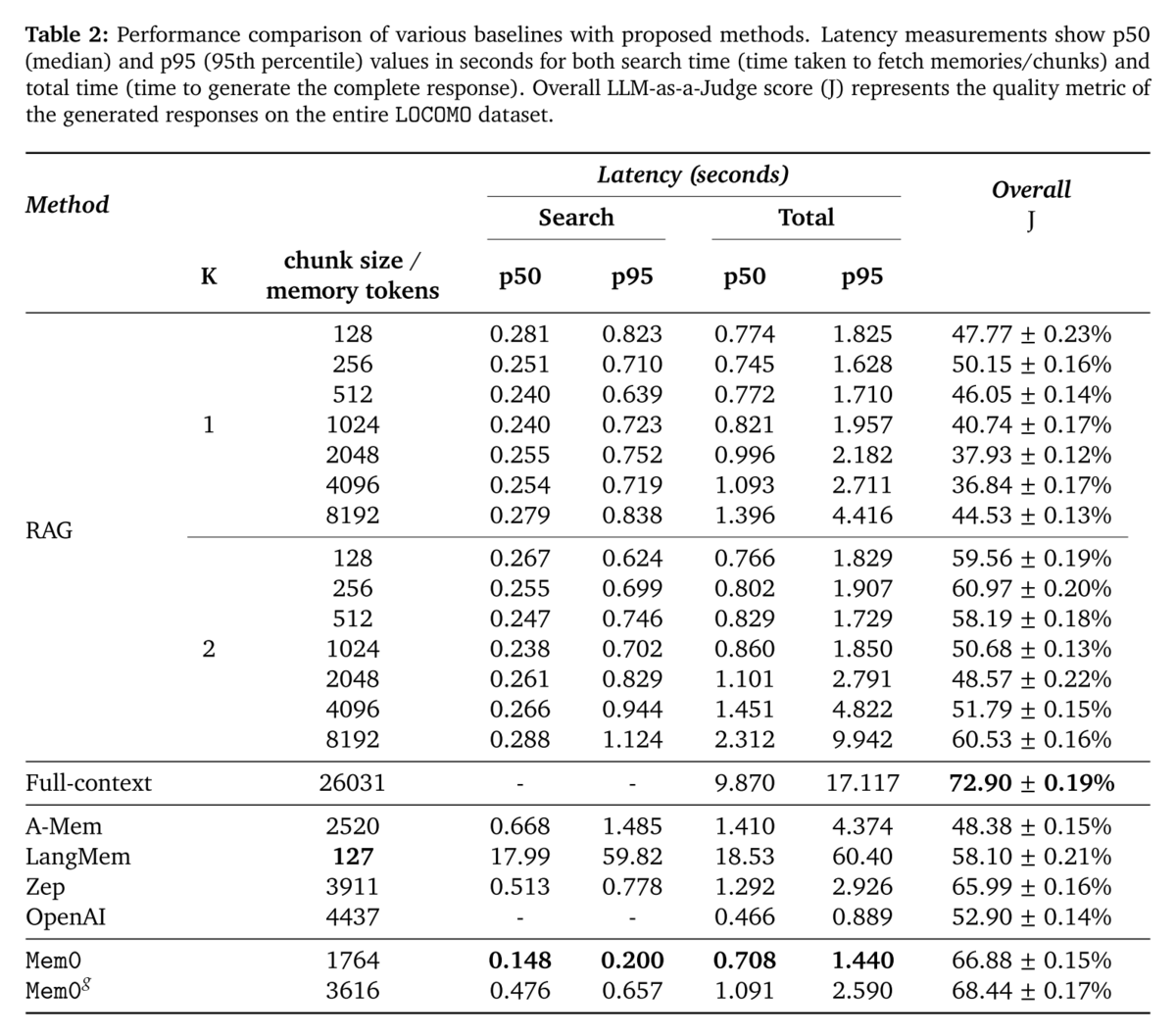
And here we see some major engineering tradeoffs - LangMem, which performed near or at the top in most of the previous metrics, has a p95 latency of over a minute, compared to under 1.5 seconds for Mem0. And we didn't even talk about token consumption required to materialize the memory store, an area where Mem0 claims a large advantage over Zep (7k tokens on average vs 600k in Zep, although 'realizing the entire memory store as tokens' is probably not a helpful 'real world' comparison of in-app token consumption for each approach).
TL:DR - if you can afford to fit all of the memories you need to search into context, and the latency of doing so is acceptable for your use case, do that. If you can't (which is the case for many applications which need to accurately retrieve data across 'long-running' interactions), and want reliable retrieval performance across multiple-conversation sessions as well as low latency, consider a solution like Mem0 or Zep.


