

How do we measure if an LLM is growing in knowledge? Historically, the answer has been simple: give it a standardized test. Traditionally, we've measured progress by their ability to ace various domain specific exams (bar, medical boards, trivia, etc). But as existing question/answer evaluation benchmarks begin to saturate, we may reach a point where static knowledge tests are no longer sufficient to gauge true intelligence. We have to stop asking what a model knows, and start measuring what it can do.
Knowledge Benchmark Saturation
One goal of evaluating LLMs is to understand where they approach 'expert level' capability in a given domain. In the ancient age of five years ago, we measured text model performance with multiple choice knowledge questions, like MMLU:

As of March 2026, frontier models are saturating benchmarks like MMLU, with the top 10 models reporting between 82% and 93% on Global-MMLU-Lite, a subset of the original MMLU evaluation focused on global knowledge and global context:
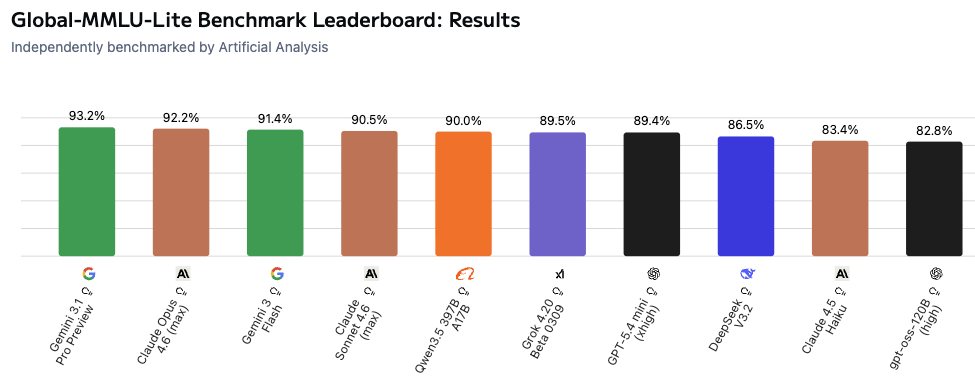
Perhaps it is unsurprising that models 'know' the answers to MMLU evaluations - these questions are well answered via direct memorization. As model size grows (either via monolithic, dense models, or larger mixture of expert architectures), the models can store more static, factual information. This saturation is driving a push to develop new benchmarks that go beyond simple information recall. For instance, in 2024, MMLU-Pro introduced a more difficult, 10 answer format (instead of MMLU's 4 multiple choice answers), and added more 'reasoning-based' questions, like this one:

These 'more difficult' questions in MMLU-Pro are hard to successfully answer via memorization, forcing models to 'think through' the given data to reach the correct answer. When MMLU-Pro was published, no frontier models exceeded a 73% success rate on the benchmark. Failure cases included reasoning errors, question understanding errors, calculation errors, and lack of specific subject knowledge. Notably, the performance of models that used CoT (e.g. "Think step-by-step...") to answer instead of 'directly' generating an answer performed significantly better on MMLU-Pro than MMLU - indicating that MMLU Pro tested something beyond simple 'answer regurgitation'.

Today, multiple frontier models all benchmark above 80% on MMLU-Pro, with Gemini 3 Flash (not even 3.1!) pushing 90%:
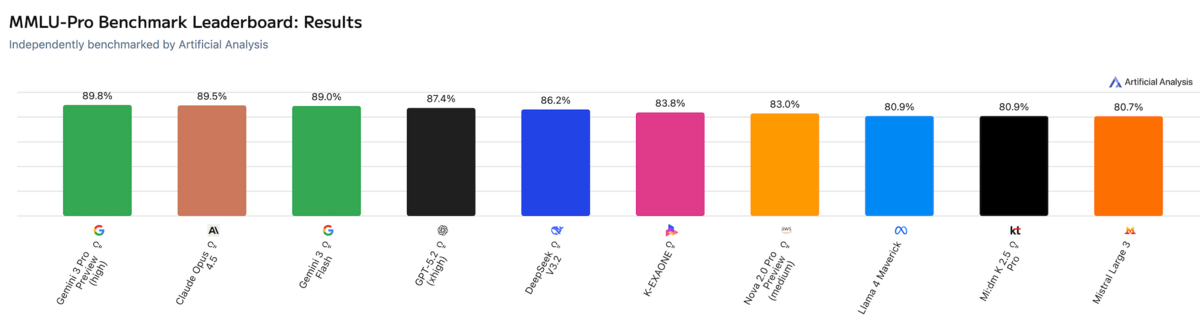
While benchmarks like MMLU still have value for identifying unexpected 'general knowledge' losses in smaller model ablation or distillation scenarios, to challenge the current frontier, new evaluations are emerging. Humanity's Last Exam claims to offer "a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage", and the results are compelling - no frontier model currently even reaches 45% success rate.
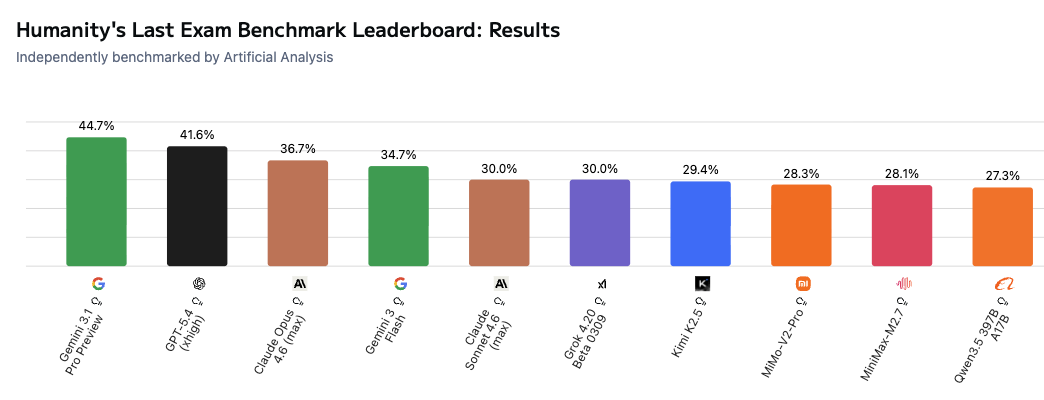
As an analogy: If the original MMLU represented pub trivia, and MMLU-Pro pushed into undergraduate course territory, HLE focuses on PhD level knowledge, generated with the help of almost 1000 professor/researcher level contributors across 500 institutions globally. Humanity's Last Exam tries to require both multi-step thinking, and extremely deep domain knowledge (not generally 'solved' on the broader internet). Some example questions from HLE help illustrate this:
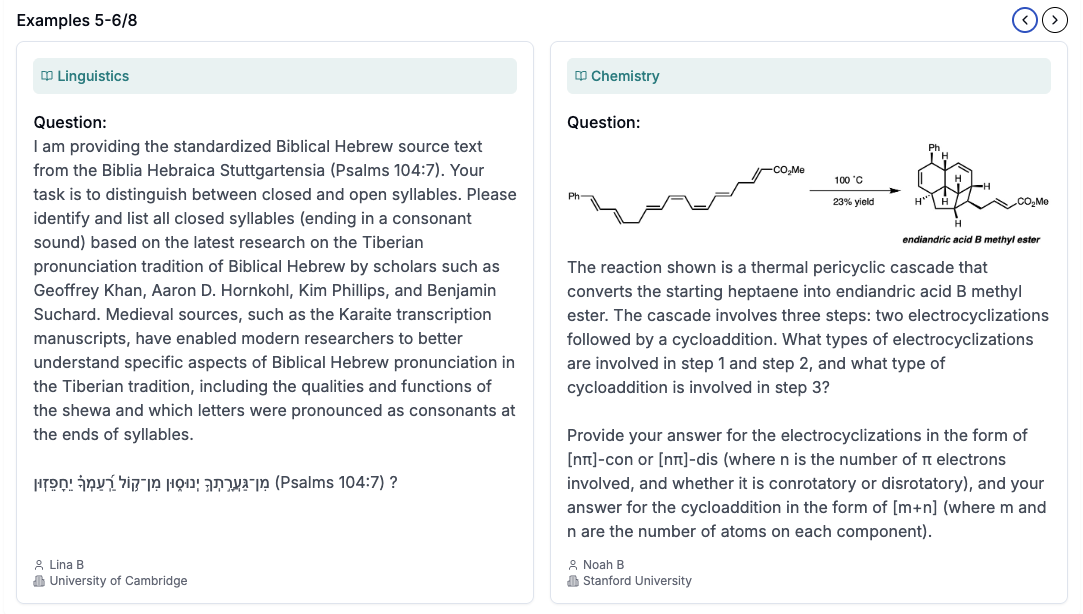
But, what happens if (when?) models eventually saturate 'expert level questions' like what HLE presents above - are models done improving? Intuitively, there is a sense that expert level work goes beyond 'getting the answer right'. A human PhD doesn't just stare at a piece of paper and generate an answer. They formulate hypotheses, run experiments, write and test code, search the internet, use external software, make mistakes, and correct their approach over days or weeks. How might one test this kind of capability, then?
Give Models the Tools
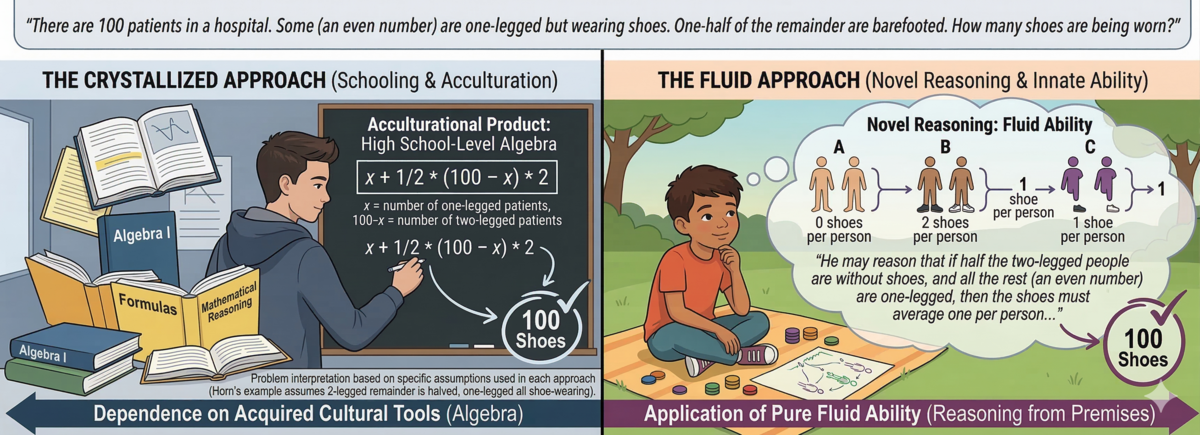
If traditional evaluations (MMLU, MMLU-Pro, even HLE) measure 'what a model knows' parametrically, agentic evaluations (indirectly) measure 'how well can a model use tools to accomplish a given task'. The first approach represents crystallized intelligence, but agentic evaluations move towards measuring fluid intelligence (the ability to solve problems abstractly, independently of having seen them before). For example, if we ask a question about how many patients in a hospital are wearing shoes, there are at least two distinct 'approaches' to the problem. The first approach applies high school algebra (the 'crystallized' approach), and the second involves a solution that bypasses mental math altogether.
In an agentic workflow, the model doesn't need to perfectly compute the algebraic steps within its own neural network weights, essentially 'memorizing' formulas. Instead, it relies on its liquid intelligence: it writes a quick Python script, executes it in a secure terminal, reviews the output, and uses that definitive result to answer your question, or to refine a script and reason through its own work. Instead of memorized formulas, the model leverages tool use, iteration, and verification.
SWE-Bench: Real World Code Issues
So, what does a practical agentic evaluation look like? Lets look at SWE-Bench, which asks models to generate a patch that will fix an actual issue from a real codebase. The issues were generated from real-world Github PRs that resolved at least one Github issue, and updated tests as part of the PR. For each issue, the benchmark clones the code repository into a Docker instance, and asks the LLM to resolve the issue. Once the LLM finishes its work, the benchmark runs a set of (hidden from the LLM) unit tests to confirm that the issue is successfully resolved.
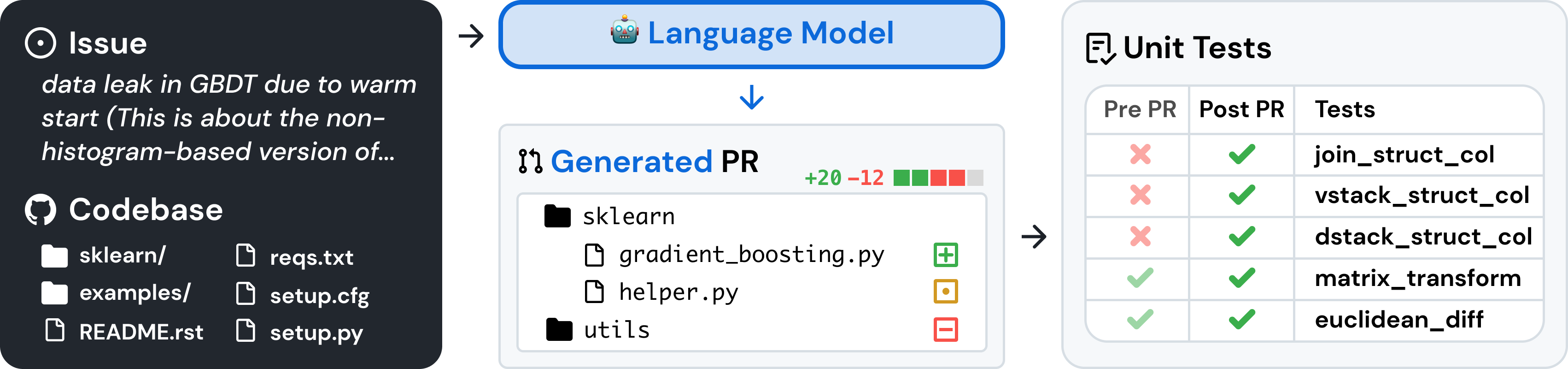
When SWE-Bench was first introduced, models struggled to solve even single-digit percentages of the issues. A simple 'this is the answer to the issue' is insufficient - the answer required comprehension of the codebase, and reasonable decision making about the correct changes to make to resolve the issue.
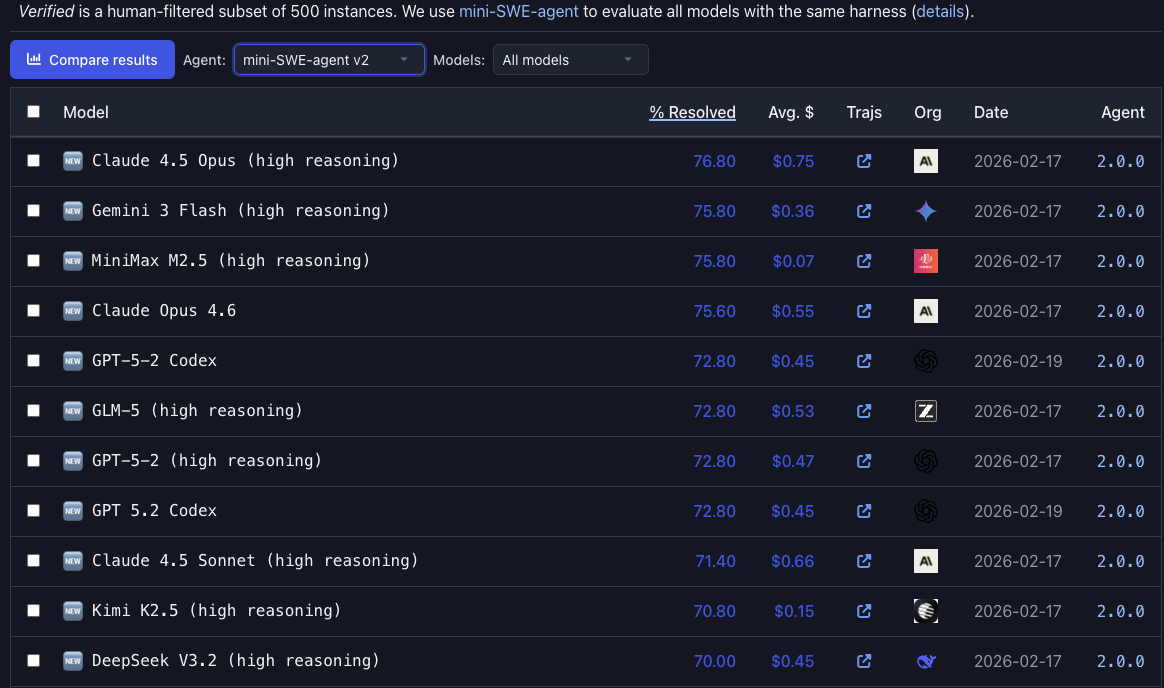
Today, however, frontier models and specialized coding agents are excelling on SWE-Bench - on a verified subset of questions from the benchmark, using a common test harness, top models generally exceed 70% successful resolve rates, at a 'price per issue resolved' between $0.30 and $0.75 USD (Kimi K2.5 and MiniMax M2.5 as extremely low cost outliers):
So, if SWE-Bench evaluated the 'liquid intelligence' of a specific aspect of software engineering (straightforward resolution of bugs/issues), how might similar evaluations benchmark models on other aspects of knowledge work?
OfficeQA Pro - Grounded Enterprise Reasoning
In March 2026, Databricks published a new evaluation, OfficeQA Pro, to measure performance on "navigating large, heterogeneous document corpora, identifying and retrieving relevant materials and then performing grounded analysis", or what they define as 'grounded reasoning'. While there are existing attempts to measure how well models can perform 'economically valuable' tasks (like GDPVal), these are typically much more 'closed world' evaluations, with only a handful of artifacts which are provided to the model up front - the model isn't responsible for gathering the data.
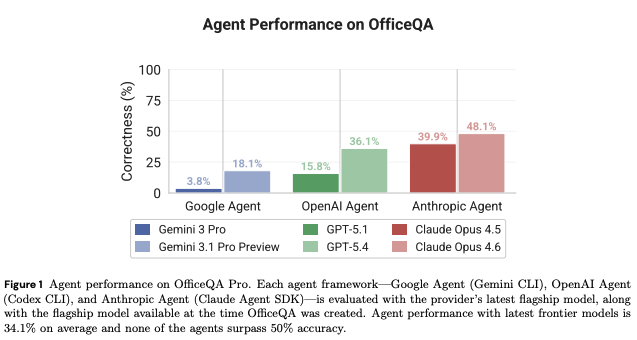
OfficeQA Pro goes beyond this, to a more messy, enterprise data environment. None of the frontier models from Anthropic, Google, or OpenAI exceed 50% on the benchmark, with only Anthropic's Opus 4.6 breaking 40%:
The dataset for OfficeQA Pro is US Treasury Bulletins from 1932 onward, which are typically 100-200 pages each, and vary dramatically based on when they were published:
From this dataset, the authors constructed questions that could not be answered by frontier model parametric knowledge alone. The questions are umambiguous and have one correct numerical answer, which cannot be found simply by 'looking up' a value in the table - they require complex reasoning over documents from multiple reports.

To answer the questions, each agent is given three tools:
- Web Search (via DuckDuckGo) for supplementary information
- Python Execution/REPL for computations and data manipulation
- File Search for exploring parsed PDF files

The agent then is given 200 rounds (maximum) to take tool actions to get to an answer. Agents are evaluated in two scenarios: first, they are given the specific pages (oracle pages) that are required to get the answer. Next, they're asked to answer the question with only the full corpus provided. The performance drops when the agent has to find the relevant information from the full document corpus, but interestingly, in a subset of 30 test scenarios, the top agents outperform or tie humans at the ask, even if allowable error in the result is increased to 5%:
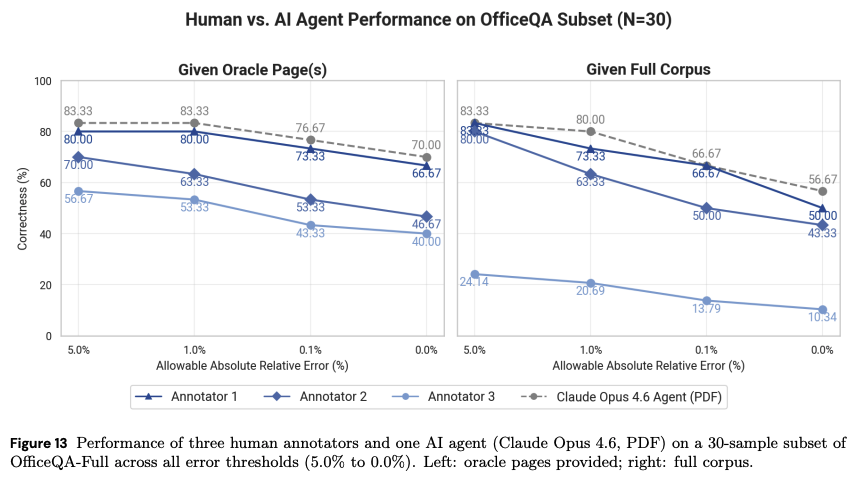
On these tasks, the authors report that human annotators take approximately four times longer than the average agent, and are about 28% less accurate in the 0.0% allowable error scenario. And, given that the top models are still below 50% correctness on the entire OfficeQA Pro dataset at 0.0% allowable error, there is room to grow.
The era of treating LLMs like prodigy test-takers is coming to a close. As models inevitably saturate traditional benchmarks, the goalposts must shift from crystallized knowledge to fluid execution.
If these systems will eventually take on longer-running delegated 'real world' tasks, our evaluations must mirror the messy, unstructured reality of actual work. In the real world, the answer isn't a multiple-choice bubble; it's a code change that implements a feature, a financial report that is factually correct and aligned with the company style, and requires use of the same systems of record that humans use. We are no longer just building encyclopedias; we are building reasoning engines. And to measure their true capabilities, we finally have to grade them on what they can actually do.


