
 methods")
The ability of LLMs to 'go from spec to code', assuming the spec is well defined, is rapidly improving. Just a few days ago, Jaana Dogan, a Principal Engineer at Google on the Gemini API, wrote about the ability of Claude Code (presumably Opus 4.5) to go from 'spec to implementation' extremely rapidly:
I'm not joking and this isn't funny. We have been trying to build distributed agent orchestrators at Google since last year. There are various options, not everyone is aligned... I gave Claude Code a description of the problem, it generated what we built last year in an hour.
— Jaana Dogan ヤナ ドガン (@rakyll) January 2, 2026
As LLMs produce more production code, plenty of companies are offering "AI Review" solutions, which provide a way to automatically catch logic errors in generated code at the merge review stage. This still involves human interaction, and follows a familiar 'identify and remove bugs after they are written into the code' workflow. More recently, human-in-the-loop specifications development (typically by iterating with the LLM to generate a "Plan" before writing the code) tries to reduce bugs by aligning what to build up front, but what if the plan itself contains errors? Can we formally verify the plan in some way before an LLM turns it into buggy code?
In December 2025, Martin Kleppmann predicted that formal methods will become more widespread, by generating trusted AI generated code with less human review, specifically predicting that:
1. formal verification is about to become vastly cheaper;
2. AI-generated code needs formal verification so that we can skip human review and still be sure that it works;
3. the precision of formal verification counteracts the imprecise and probabilistic nature of LLMs. These three things taken together mean formal verification is likely to go mainstream in the foreseeable future.
"Prediction: AI will make formal verification go mainstream", Martin Kleppmann
If 'spec first' development emerged as an AI-assisted 'best practice' from 2025, it's logical to ask how we can move the human-in-the-loop 'verification' phase up from 'review implemented code before merge' to 'review specs before implementing code'. This is where formal methods come in.
Formal Methods
In 2015, Amazon engineers wrote about their use of TLA+, a tool for formally verifying system behavior:
Amazon engineers have used TLA+ on 10 large complex real-world systems. In each, TLA+ has added significant value, either finding subtle bugs we are sure we would not have found by other means, or giving us enough understanding and confidence to make aggressive performance optimizations without sacrificing correctness. Amazon now has seven teams using TLA+
"How Amazon Web Services Uses Formal Methods"
Amazon's focus was clarity in design, not finding bugs - in other words, preventing errors by ensuring the specification is written to exclude them:
There are at least two major benefits to writing a precise design: the author is forced to think more clearly, helping eliminate “plausible hand waving,” and tools can be applied to check for errors in the design, even while it is being written. In contrast, conventional design documents consist of prose, static diagrams, and perhaps pseudo-code in an ad hoc untestable language.
"How Amazon Web Services Uses Formal Methods"
In the following decade, formal methods remained niche. A few notable packages enabled 'testing specifications' beyond unit tests; tools like Hypothesis (property-based testing), or Frama-C (verified C specifications) brought formal rigor to implementation. However, because these verify code behavior rather than system design, they are not expressive system specifications in the same sense as Alloy or TLA+.
When we talk about formal specification, there are two critical properties to understand - Safety and Liveness.
Safety and Liveness
While 'functional' and 'non-functional' requirements are valuable, and E2E/integration/unit tests help verify that a system works under specific test conditions, mathematically verifying system behavior is more rigorous. Safety ensures that specific bad states can never occur, like keeping a variable within a certain range (e.g. 'account balance >= 0 before and after all transactions'), preventing deadlock, or ensuring atomicity (no partial updates) of a value. Liveness ensures that specific 'good states eventually occur', like a firmware update completing, memory being freed after being allocated, or a packet reaching its destination.
A simple example: think of traffic lights at an intersection, and assume we care about 'no cars crashing' (Safety), and 'cars eventually travel through the intersection' (Liveness). If all lights remain red indefinitely, the intersection is safe but not live. If all lights turn green simultaneously, traffic attempts to move (Liveness), but collisions occur immediately (Safety violation). A correct system gets cars through the intersection and avoids crashes.
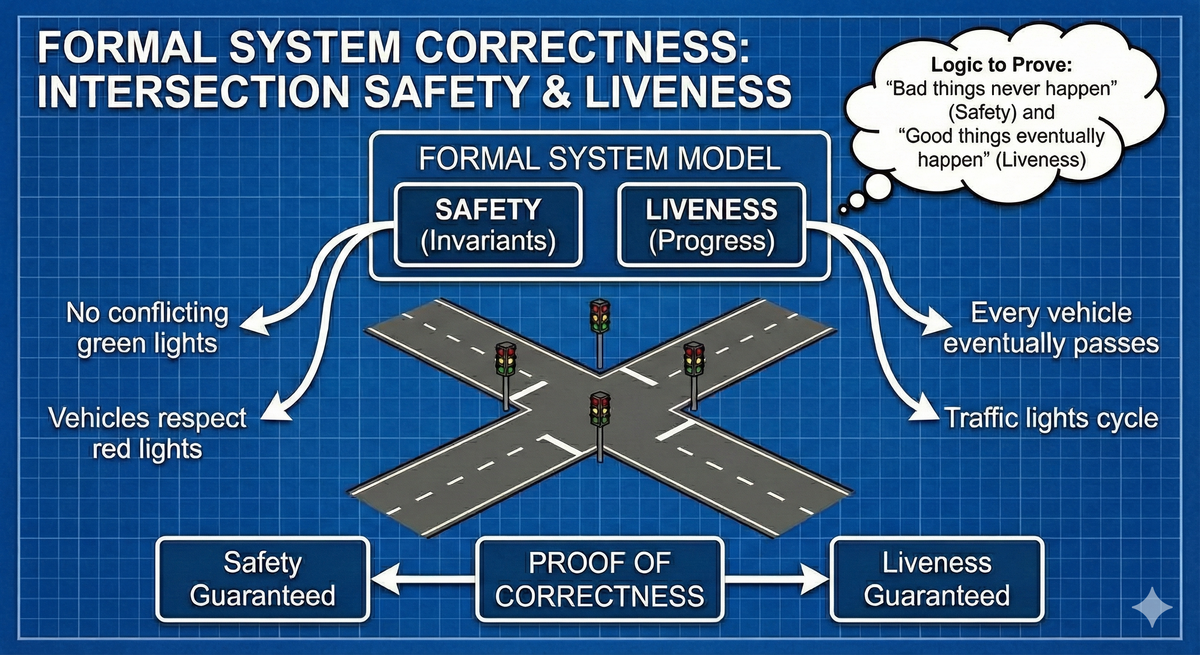
Safety can be verified on a state-by-state basis ('Have two cars collided in this state, yes or no?'). Liveness, however, is evaluated over the full execution flow of the system. We must check that from every possible starting state, as the system runs forward indefinitely (entering some state cycles, as traffic lights in normal operation don't reach an 'end state'), the desired good thing (e.g., green light for each path into the intersection) eventually happens.
Putting it together, "correctness" is the intersection of safety and liveness. If all possible system behaviors (execution traces from all possible starting states) are both safe and live, the system is formally correct.
LLMs and Formal Validators
What if we combined the ability of LLMs to generate code from specifications with tools to formally verify that a specification covers all of the edge cases, before writing the code? The authors of "From Informal to Formal -- Incorporating and Evaluating LLMs on Natural Language Requirements to Verifiable Formal Proofs" ask the same question, and explore the performance of different LLMs across different formal verification languages.
Figure 1 from the paper explains the difference between using formal methods in the development process and more ambiguous spec-driven development:
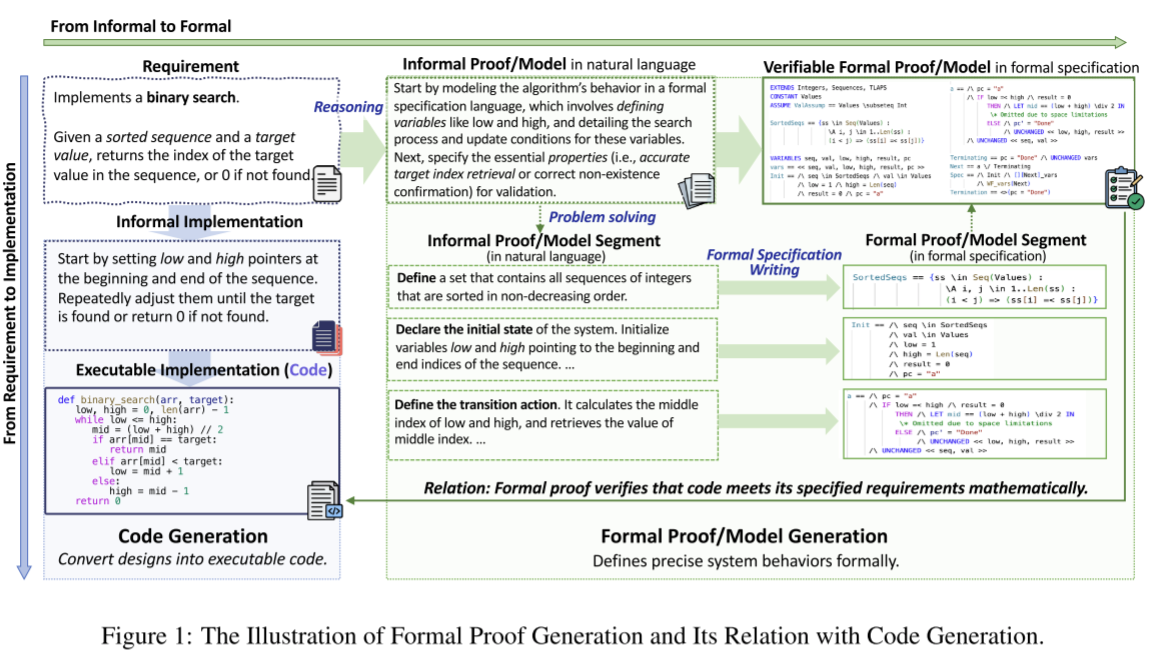
One of the key points of the paper is that "Proof Generation" tasks have a high success rate with LLMs, and fine-tuning small (~8B) models match proof generation performance of much larger models. The paper explores Coq, Lean4, Dafny, ACSL, and TLA+ as downstream verification tools, and implements a 6 step process to go from 'informal specification' to 'formal proof':
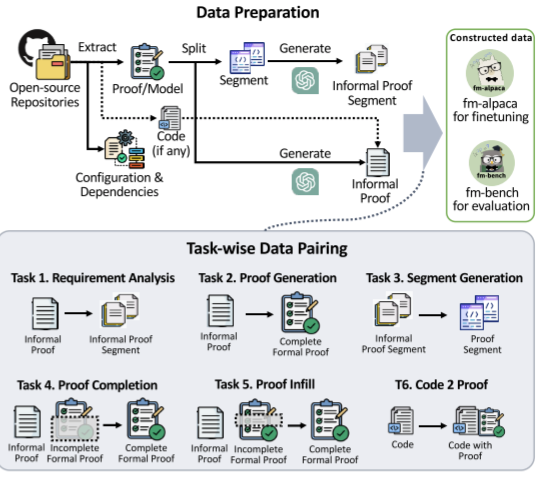
These tasks test the ability to decompose informal requirements into sequential steps in natural language (English), generate complete proofs from natural language descriptions, generate proof segments from segments of specifications, complete partial proofs (similar to code completion), fill in a proof that has portions masked (but has content before and after the masked sections), and generating proofs from code (working backwards from implementation to specification).
A particularly interesting result, though, is the capability of small models (like Llama 3.1 8B) to exceed 95% accuracy in generating 'partial proofs' in ACSL after fine-tuning, from Table 3 in the paper:
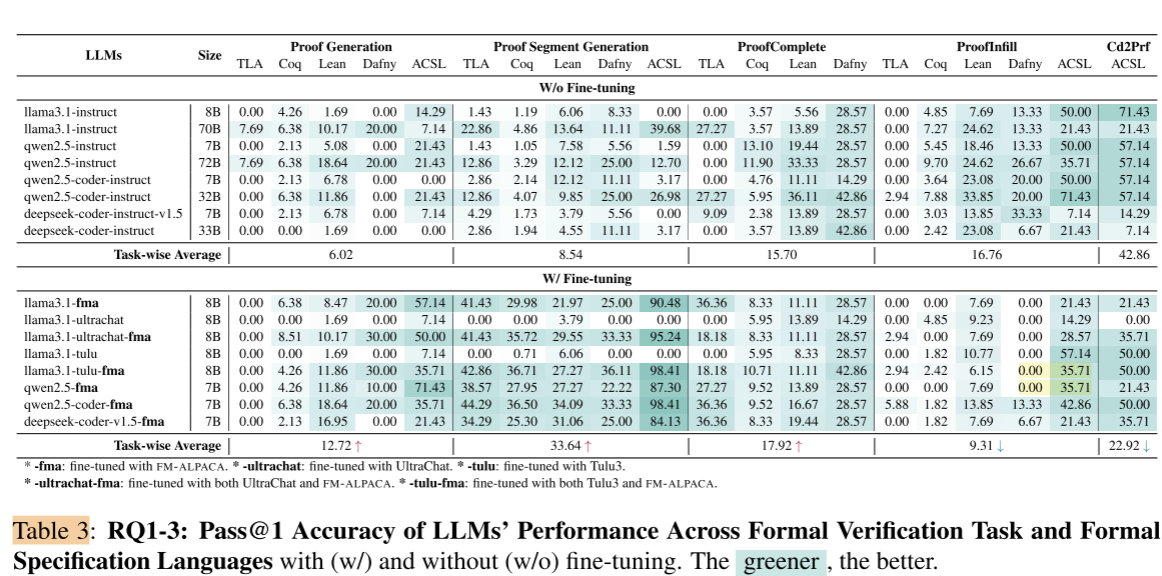
If fine-tuned, small (8B) LLMs can generate valid proofs in January 2026, it suggests that LLM-assisted formal verification is not a 'distant' possibility, and that hallucinations may matter less in the near future. If an LLM generates code and a related proof from a specification, a verifier can check the proof against the specification (highlighting where there are variations), and feed that back to the LLM to correct the error, until the specification and formal system proofs align. But what about verifying the implementation itself?
Implementation Verification: Dafny
Dafny is a formal tool and 'provable' programming language that sits close to the final implementation, in that it transpiles into executable code (Dafny code transpiles directly into C#, Javascript, Go, and Python). Dafny answers the question "Does my code implement the specification correctly?". A screenshot from the VS Code Extension documentation clarifies what this means in practice:

Notice that in the above, the developer specifies a postcondition on the function - that the 'more' variable will always be greater than or equal to the 'less' variable (this is the 'ensures less <= x <= more' segment). The highlighted blue text shows a case where Dafny demonstrates this invariant is violated - thus, the function does not do what the developer specified (when y is negative and x is zero). This is a toy example, but highlights the power of formal verification to identify issues without explicit test cases. If a property of a function can be expressed as a formal specification, tools like Dafny can 'prove' whether that condition is met in all scenarios, increasing confidence in the code.
One downside of a solution so closely tied to the implementation is the fact that the languages Dafny compiles to will have more expressive syntax than Dafny itself. For example, trying to model reflection or heavily dynamic typing is likely to be difficult in Dafny - although standard libraries are emerging. Looking at the transpilation from the 'upstream' direction, it is not likely that the Python generated from this process aligns well with what a human would write 'by hand' - the idea being the human interface moves up to Dafny, while the Python (or other transpiled result) becomes a build artifact.
I've put together a repository to demonstrate how LLMs can turn 'natural language' specifications into Dafny specifications. Take this 'binary search' function skeleton:

If I run the above example (which lacks Dafny specifications, just has my informal 'TODO' spec comments) through the Dafny CLI, I see an error - Dafny recognizes that we've put no limits on `mid`, which means `mid` could be out of the array range:
➜ dafny git:(main) dafny verify binary_search_skeleton.dfy
binary_search_skeleton.dfy(17,8): Error: index out of range
|
17 | if a[mid] < key {
| ^
Dafny program verifier finished with 0 verified, 1 errorNext, lets provide the above 'skeleton' snippet (with the informal natural language comments) into a modern LLM (Claude Sonnet 4.5, Gemini 3 Pro, etc). After doing so, you'll get a result roughly similar to this completed snippet, with valid Dafny specifications inserted:

This is a compelling result. I was able to take a function that was 'apparently correct', then write natural language specifications for the function describing that 'correct' behavior, and have the LLM translate that into a formal specification. Then, with the Dafny CLI, I can verify that the binary search with specification passes verification - it works as specified:
➜ dafny git:(main) dafny verify binary_search.dfy Dafny program verifier finished with 3 verified, 0 errors
If you (or an AI) can write sections of a program in Dafny, and the specifications for those sections are correct, Dafny can prove that the code works correctly, for all possible inputs - far more confidence inspiring than even LLM-assisted TDD.
What Dafny cannot do, though, is generate confidence in the overall system design. Per-function specifications are great at catching implementation bugs, but they don't address specification problems. This is where languages like TLA+ come in.
Notable Mention: DafnyPro, presented this month at the Principles of Programming Languages (POPL) conference, promises to take existing programs and annotate them with Dafny, which could be used in a continuous development flow to help verify that code changes maintain the expected system properties. I'd be surprised if we don't see a wave of 'formal verification + LLM' CI solutions (via new entrants or new features for existing "AI Review" checkers) emerge in 2026.
Specification Verification: TLA+
Contrasting with Dafny, TLA+ specifications generate a state machine representing a system, not executable code. While Dafny verifies the implementation, TLA+ verifies the logic of the design.
As these tools enter the mainstream, a possible workflow looks like:
- Prompt: A human describes a complex system in natural language (e.g., a distributed lock).
- Prompt to Formal Model (LLM): An LLM generates a TLA+ specification from the natural language prompt
- Validator: The TLA+ Model Checker (TLC) exhaustively searches every possible state. If it finds a "Safety Violation" (two nodes holding the same lock), it provides a counter-example trace demonstrating the failure.
- Iterate: The LLM uses that trace to fix the spec (which might involve human-in-the-loop to approve a functional change in the natural language specification)
This creates a "Self-Correcting Spec" loop. By the time the developer reaches for a tool like Claude Code to actually write the implementation, the blueprint is mathematically guaranteed to work. As tools like Dafny are adopted to bridge the gap between 'system specification' and 'implementation specification', the risk areas move further up the chain - to the specification itself - and 'hallucinated code' becomes less of a problem.
Now, for an example. Lets take an incomplete TLA+ specification for two processes that need to share a critical section of code, described as:
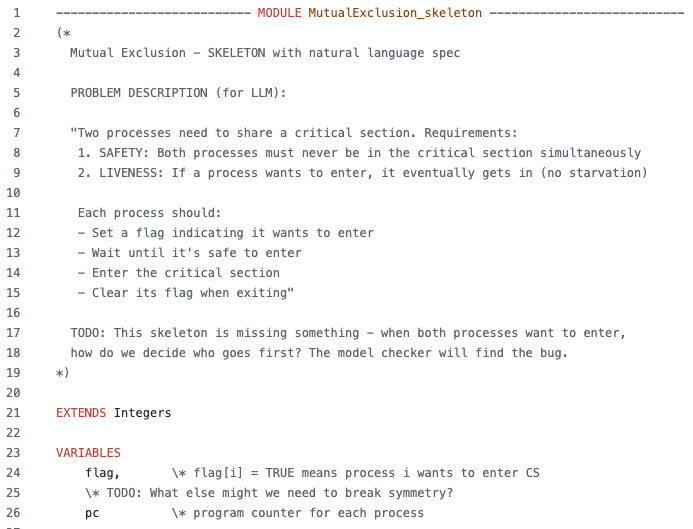
When I run the skeleton specification through the verifier, I see a deadlock is detected:
➜ tlaplus git:(main) java -jar ~/.tla/tla2tools.jar -config MutualExclusion_skeleton.cfg MutualExclusion_skeleton.tla ... Semantic processing of module MutualExclusion_skeleton Linting of module TLCExt Linting of module _TLCTrace Linting of module MutualExclusion_skeleton Starting... (2026-01-13 13:45:45) Implied-temporal checking--satisfiability problem has 2 branches. Computing initial states... Finished computing initial states: 1 distinct state generated at 2026-01-13 13:45:51. Error: Deadlock reached. Error: The behavior up to this point is: State 1: <Initial predicate> /\ flag = (0 :> FALSE @@ 1 :> FALSE) /\ pc = (0 :> "idle" @@ 1 :> "idle") State 2: <SetFlag(0) line 38, col 5 to line 40, col 41 of module MutualExclusion_skeleton> /\ flag = (0 :> TRUE @@ 1 :> FALSE) /\ pc = (0 :> "waiting" @@ 1 :> "idle") State 3: <SetFlag(1) line 38, col 5 to line 40, col 41 of module MutualExclusion_skeleton> /\ flag = (0 :> TRUE @@ 1 :> TRUE) /\ pc = (0 :> "waiting" @@ 1 :> "waiting") 9 states generated, 7 distinct states found, 2 states left on queue. The depth of the complete state graph search is 4. Finished in 05s at (2026-01-13 13:45:51) Trace exploration spec path: ./MutualExclusion_skeleton_TTrace_1768329945.tla
Then, if we copy both that error trace and the "Skeleton" TLA+ file to Gemini 3 Pro, it will produce something similar to the 'corrected' version, which adds a 'turn' variable, which is set to 'the other process' whenever exiting the critical section of code. When both are waiting, whoever last touched the turn variable loses — they overwrote turn (which they only ever write to give control to 'the other process'), so the other process enters first. No deadlock, which implements Peterson's algorithm:

Closing Thoughts
Providing feedback loops and ways for LLMs to 'check their work' is standard practice for shipping production code with AI. As formal methods become more usable, they'll move from solutions that are used for critical systems at global scale (like Datadog) to something that is integrated into the development process (whether as part of the harnesses like Claude Code and Antigravity, 'roll your own' in CI pipelines, or via existing providers augmenting their code review offerings)


