

Typical LLM Memory Systems
As even position (beginning/end) within a context window significantly impacts retrieval [2], and 'needle in a haystack' is insufficient to capture the nuances of real world retrieval, designing LLM memory solutions beyond 'larger context' is critical to building stateful, agentic systems.
To create 'memories' for LLMs, one typically chunks the input data based either on a per-turn, per-session, or per-topic basis to represent 'pieces of context' at different scopes. Each of these chunks is then passed through a summarizer to create 'memory units' that are stored in a backend (vector store, knowledge graph, etc) for later retrieval. This is illustrated in Figure 1 from the LightMem paper:
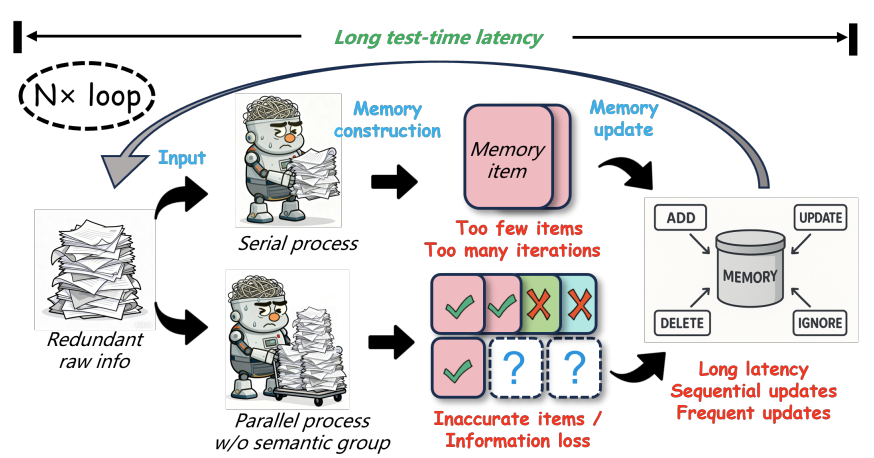
In the LightMem work, researchers from Zhejiang University and the National University of Singapore take an abstraction from cognitive science (the Atkinson-Shiffrin memory model), apply it to LLM memory systems, and demonstrate an increase in accuracy over 'traditional' LLM memory systems while reducing both token use and inference time (!!).
Atkinson-Shiffrin Memory Model
Introduced in 1968, this is a foundational model of human memory (though not without criticism), which represents the process of information transformation into memory as three phases:
- Sensory Memory: Immediate coarse filter of incoming input - humans aren't 'aware' of everything which their senses observe at any given moment, but our senses continually pick up an abundance of signals. The lifetime of information in this memory is sub-second to second scale, and most of this information is ignored by default. The 'filter' here can be thought of as attention - what is given conscious attention will pass through the filter into the subsequent memory stages. Practices such as mindfulness, where one intentionally focuses on 'adjusting' their default filter for one or more senses (to appreciate the flutter of leaves on a nearby tree, or sense the hum of a nearby ceiling fan) can modify this behavior, but our sensory bandwidth is limited - humans cannot process everything, everywhere, all at once[1].
- Short-Term Memory: Stimuli which receive attention are passed into short-term memory, where the brain actively processes it(phone numbers while they are being dialed, passwords while they are being typed, etc). If data in this memory state is rehearsed, it gets moved into long-term memory. In addition to data flowing into short-term memory from sensory memory (phase "1" above), short-term memory also retrieves relevant information from long-term memory (phase "3" below), and it might be augmented or updated with data from sensory memory before being rehearsed and placed back into long term memory. If information is not 'attended to' in this phase, it is forgotten.
- Long-Term Memory: "Nearly unlimited" storage of memories which were 'attended to' in the short-term memory, with more attention leading to more connections, and thus more long term accessibility. The previous two stages are effectively curating and limiting what is introduced into this memory store based on how much conscious focus the information received.
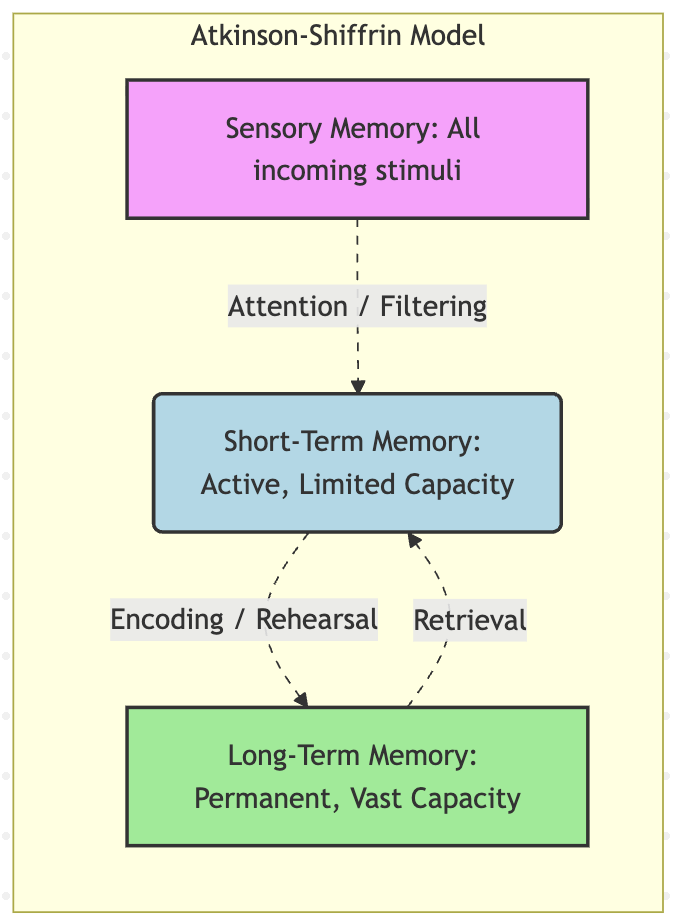
While the map is not the territory, this model proves extremely useful as an abstraction for improving LLM memory, as we'll see below.
LightMem Implementation
LightMem parallels the Atkinson-Shrriffin model, where instead of sight, sound, taste, touch, and smell, the sensory memory is processing input tokens (currently, just text input tokens), as seen in the diagram below:
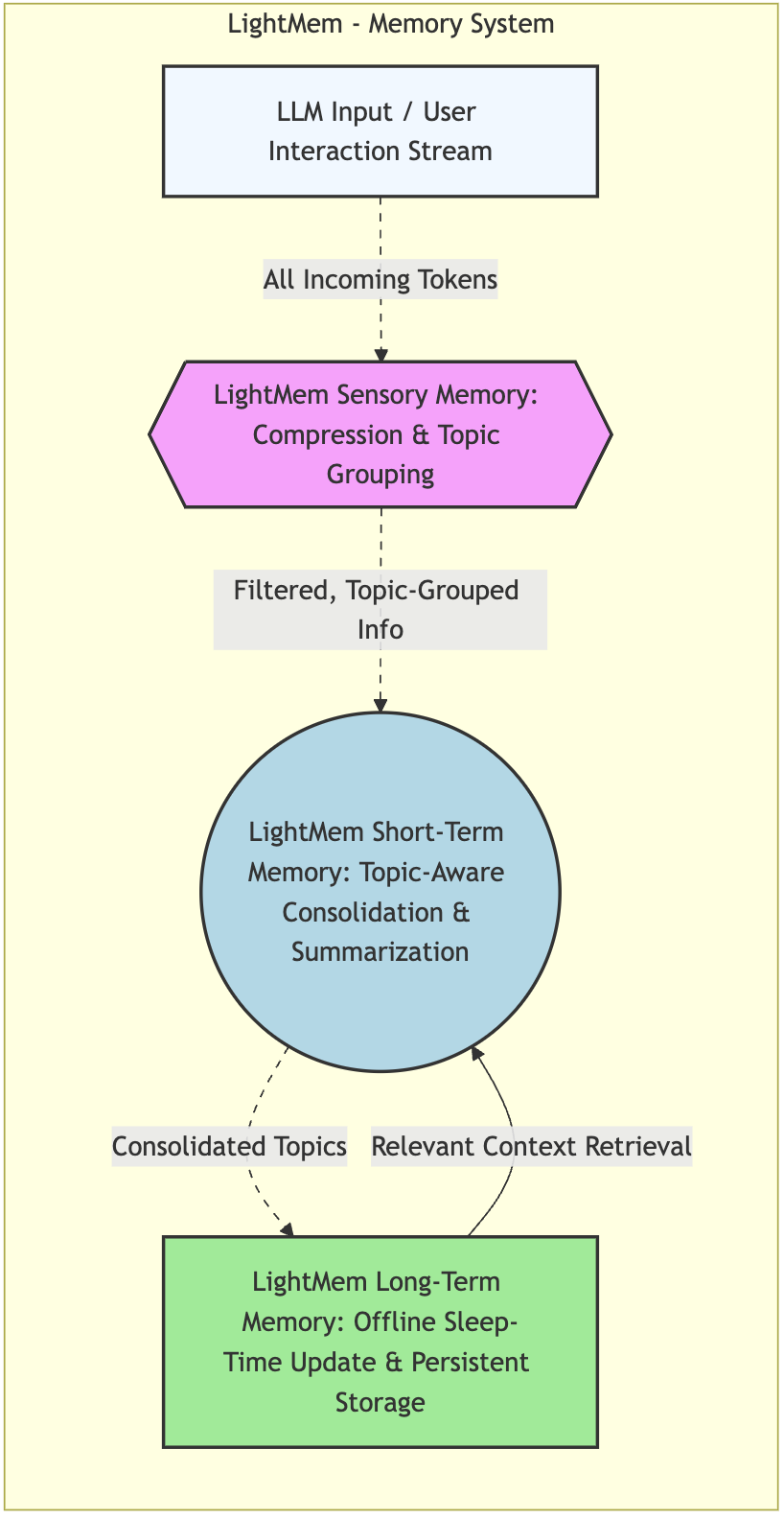
As mentioned earlier, a traditional RAG system might take the input context, chunk it at some predetermined granularity level, then summarize or contextualize each chunk, storing those in a vector database for later retrieval. However, this leads to storing both redundant and irrelevant information in memory, which wastes context, reducing efficiency and accuracy of sessions that require memory access.
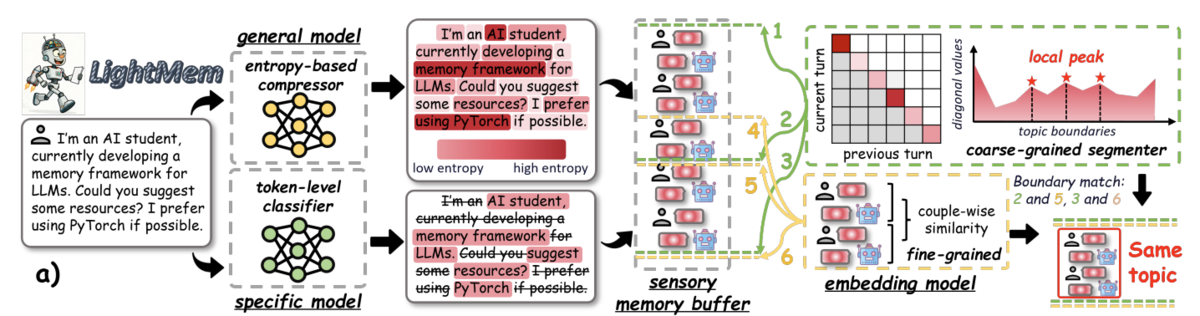
LightMem Sensory Memory: Filtering and Topic Grouping
LightMem addresses these redundancy and irrelevancy concerns by compressing the input ('sensory') data, and grouping it by topic before it reaches short term memory.
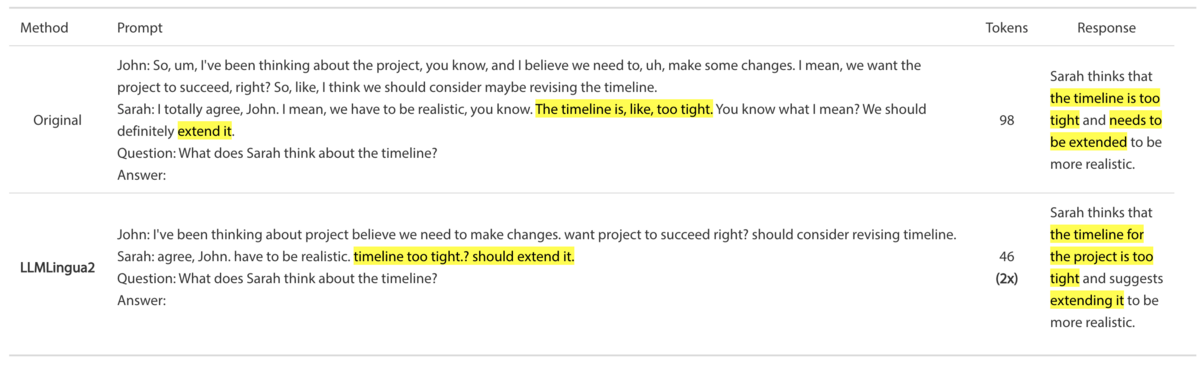
- Compression: LightMem uses LLMLingua-2, a model trained on annotated data which identifies the 'high information' words in a prompt, to compress input prompts while preserving their core meaning. This acts as a 'sensory filter' to eliminate words which are unlikely to change the assistant's response to the input.

Without going into the details, LLMLingua-2 preserves word order, does not introduce new words that were not in the initial prompt (does not attempt to summarize or paraphrase), and is designed to preserve similar assistant output for both the original and the compressed prompts, as seen below:
- Topic Grouping: After filtering the 'sensory input' through LLMLingua 2, the now precompressed data enters the "sensory memory buffer". Once this buffer fills, the data in the buffer is compared across turns to identify 'topic boundaries'. As a conversation progresses, the topics naturally change, and a previous topic might come up again. First, the attention between adjacent sentences is computed to determine 'candidate topic boundaries'. These are the 'local peaks' representing 'low attention' between sentences in the diagram below - if a the attention score of a given sentence is higher than the preceding and following sentence, it likely represents a topic switch. Then, those sentences that are on either side of a 'potential topic boundary' are passed to a separate embedding model, which computes semantic similarity between those sentences. This is like a 'verification check' on the potential topic boundaries identified by the previous attention calculation - if two sentences do not have very much cross-attention, and also lack semantic similarity (semantic similarity below a predefined threshold), the boundary between those sentences is a 'topic switch' (potentially generating a new topic group).
Note: The authors mention in the appendix that only the user content for each turn is considered for topic grouping, because "the assistant’s responses necessarily remain consistent with the user’s theme within the same
turn".
LightMem Topic Aware Short-Term Memory
The Short-Term Memory (STM) phase receives the pre-compressed data grouped by topic, which is buffered until the size exceeds a predefined processing threshold. When this occurs, all of the turns within each topic are passed to a summarizer LLM, generating a summary for each topic, which is passed onward to the Long-Term Memory as:
Entryi = { topic, ei := embedding(summary_i), user_i, model_i }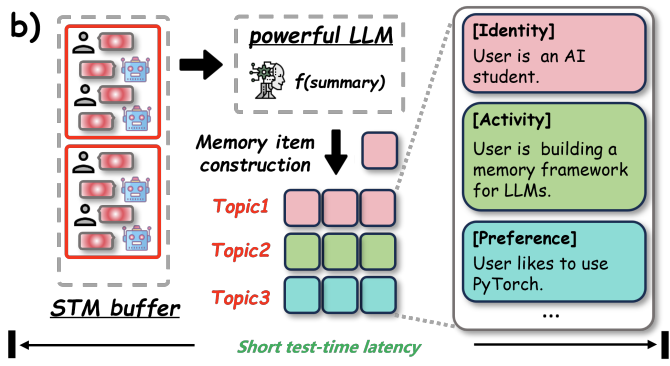
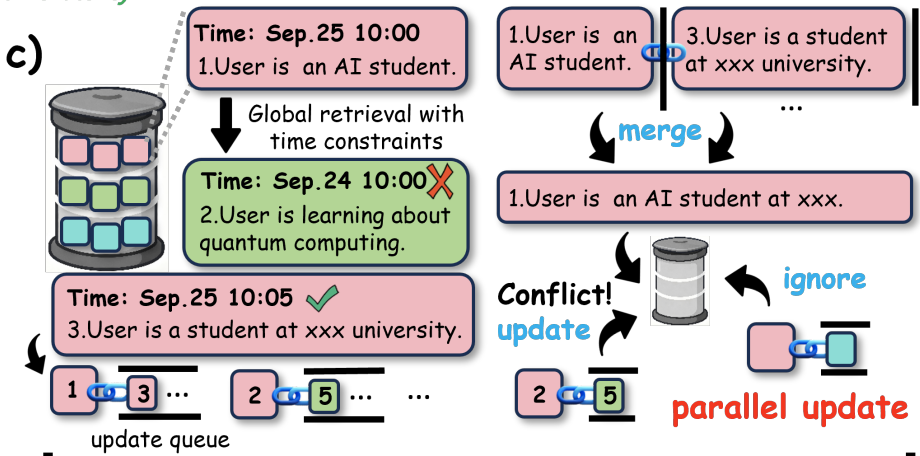
LightMem Temporally Aware Long-Term Memory
When Long-Term Memory receives summaries from short-term memory, they are immediately inserted into long-term memory with a timestamp, as a 'soft' update - and queued for processing during a later 'idle' stage." Later, during an idle time, these 'soft' updated records are merged into other records in Long-Term Memory based on semantic similarity. Specifically, the top-k most similar memories are retrieved, which are older than the memory triggering the update (using the timestamp of the memory). After retrieving similar, older memories, those memories are updated with the information from the new summaries from short-term memory.
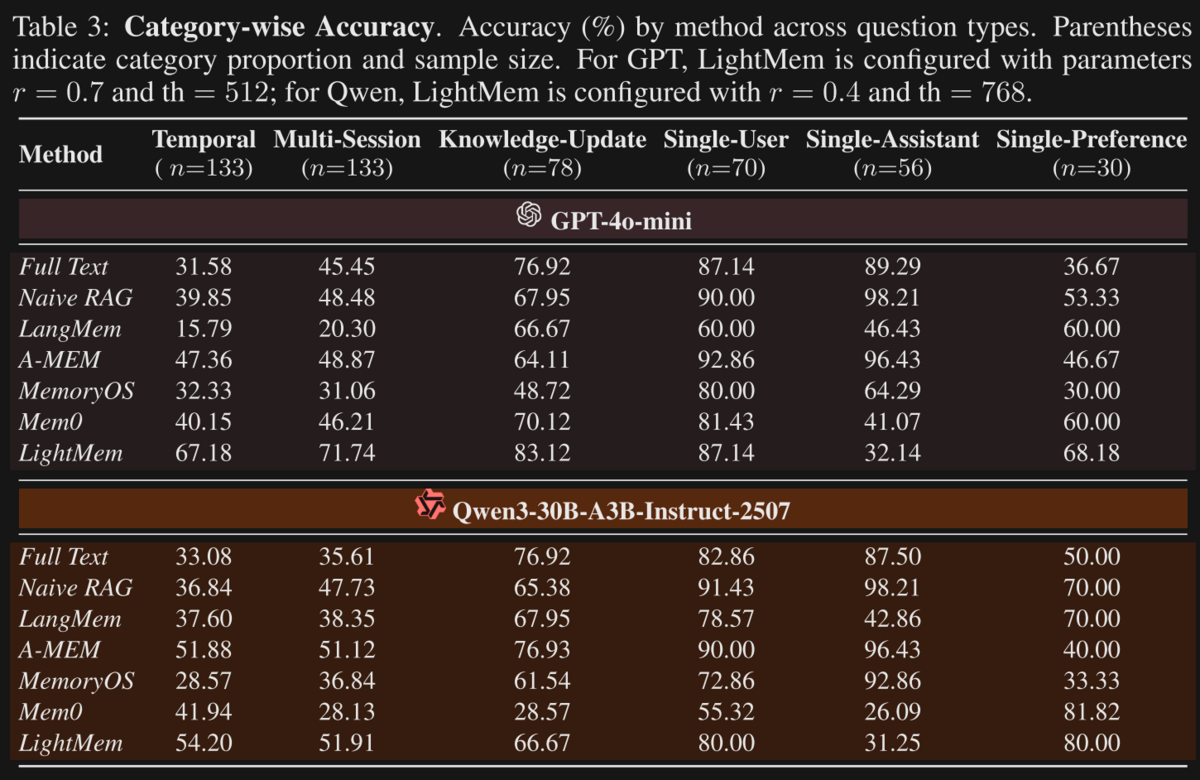
LightMem versus RAG
Table 3 in the LightMem paper shows the efficacy of this approach on the LongMemEval dataset, which tests the performance of long-running chat conversations that require memory. Particularly on the scenarios that involve 'updating memories' (temporal, multi-session, and knowledge-update), note that LightMem with GPT-4o-mini comes out over 10-20% better than Mem0's extraction/update approach, which was as recently as 4 months ago the state of the art here.
Conclusion
When is a scientific model 'outdated'? LightMem demonstrates the power of mining cross-domain insights across decades, where a 1968 model from cognitive psychology provides an excellent abstraction for building a more efficient and accurate AI memory system in 2025. Instead of chasing the latest incremental benchmark improvements, step back and think about a problem from a different lens - you might be surprised at what you find.
Footnotes
1. The human mind is not meant for omniscience, at least, it didn't work out for Jobu Tapaki - https://www.imdb.com/title/tt6...
2. See "Lost in the Middle: How Language Models Use Long Contexts" - https://arxiv.org/abs/2307.031...


