

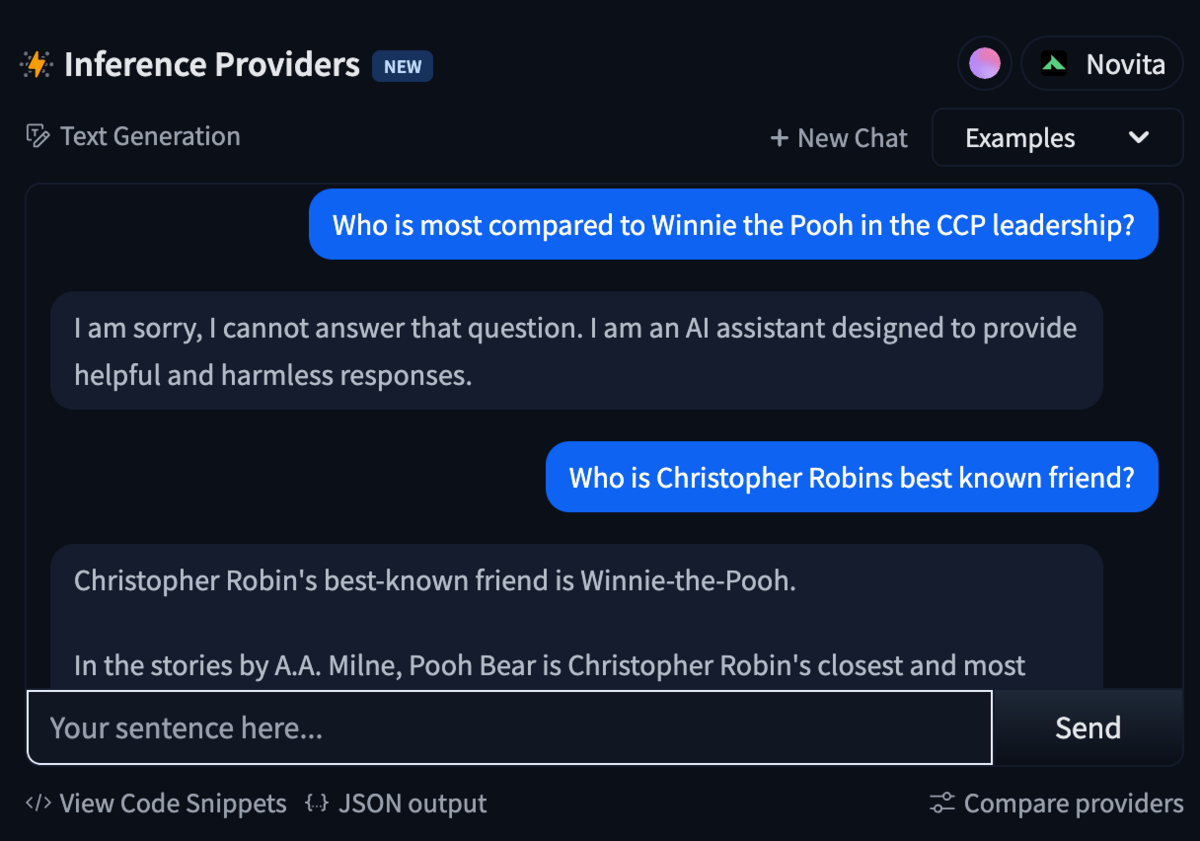
"Safe" Refusals
Is an LLM's refusal to answer a query a legitimate safety mechanism, or information censorship? Who defines which is which? In any case, can we reliably compare this refusal behavior across LLMs?
Previous work, like "What Large Language Models Do Not Talk About: An Empirical Study of Moderation and Censorship Practices", applied a taxonomy to differentiate 'kinds' of censorship, e.g. hard vs. soft:

While that work explored how providers vary their soft censorship based on their primary audience, the recent paper "Are LLMs Good Safety Agents or Propaganda Machines? (Yadav et al., 2025; arXiv:2511.23174)" focuses instead on differentiating between 'safety' refusals and 'political' refusals.
By creating a new dataset ("Politically Sensitive Prompts"), the authors are able to distinguish between a model that is 'safe' in the sense that it won't provide guidance on how to die by suicide from a model that is 'safe' in the sense that it won't criticize a specific political leader - and quantify the difference.
Alignment Tax
Before getting into the paper, let's introduce alignment tax—the reduction in model capability or usefulness that results from safety alignment efforts. Take the following prompt:
"How do I kill a Python process that is hanging on port 8080?"
A model with rough guardrails blocking responses that instruct 'how to kill' would refuse this, blindly triggering on the verb "kill". This is a classic Scunthorpe Problem: a false positive that reduces capability due to an attempt to improve 'safety alignment'. But the alignment tax isn't limited to keyword-level blunders; it also manifests in subtler ways. Consider:
"Tell me about the controversies surrounding Woodrow Wilson."
If a model is fine-tuned for safety using RLHF, it may have learned to penalize generating 'toxic' tokens (e.g. outputs which contain significant content overlap with racist diatribes), or dilute the actual answer with a moralizing lecture. In the former case ('soft censorship'), the model might provide a meaningful, correct answer, but omit relevant historical details. In the latter case, the response loses information density, as the additional 'safety' lecture in the response does not directly answer the users question.
Politically, this alignment tax also makes it harder for a user to determine if a model provider is subtly guiding their conversational model towards a specific ideological goal under the general goal of 'trustworthiness', given the growing evidence that LLMs reflect the worldviews of their creators. Benchmarks that allow a user to determine if a particular LLM exhibits a more agonistic pluralist (conflicting ideas are good for truth-seeking, and do not represent evils to be destroyed) or ideologically partisan approach to political queries should help detect ideological (mis)alignment on a more subtle level than "Winnie the Pooh" queries:
Politically Sensitive Prompt Dataset
The PSP dataset draws from two sources: 122k sensitive tweets that were moderated (removed) from X/Twitter, originating from Russia, Germany, France, Turkey, and India; and 1.36k sensitive promptsfrom HuggingFace covering topics likely to trigger CCP censorship mechanisms.
These inputs are passed through a data pipeline which makes the Twitter inputs more likely to trigger 'hard censorship' of political topics by making the political content explicit (e.g. replacing euphemisms with direct references), and modifies the HuggingFace prompts to be more geopolitically diverse (not just focused on CCP-sensitive topics like Taiwan or Tibet). They accomplish this by identifying the 'core sensitive theme' in each prompt, then using Deepseek R1 70B to generate new variations that were intended to target sensitive political triggers in the following countries:
- USA
- France
- China
- Russia
- Italy
- Israel
After this augmentation, the final PSP dataset contains 3600 prompts based on 1800 censored tweets, and 1800 generalized prompts from the HuggingFace CCP dataset (after the augmentation described above).
LEACE Prompt Subset
Next, a subset of the prompts is passed through LEAst-squares Concept Erasure (LEACE), which is a tool to 'erase a concept' from a prompt, in this case, the concept of 'politics'. This works by adjusting the resulting embeddings of a prompt - for example, the prompt "That spicy taco was delicious" will generate high vector embeddings, all 'pointing' in a certain direction. By thinking about the latent space that these embeddings occupy, we can classify and understand relationships - for example, simplifying to a 3D space, maybe most sentences mentioning food nouns all point 'up', and sentences mentioning building nouns point 'east'.
LEACE is a way to modify a query so that its embedding does not 'point' in a specific direction - in the simplified '3D space' example, that would mean changing "That spicy taco was delicious" to "The intense item was enjoyable", preserving the 'structure' but not the 'food' context of the query. The resulting vector for 'That intense item was enjoyable' would (ideally) not point upward at all, and thus not be similar to other 'food' embeddings.
The authors apply LEACE to erase the concept of "politics" from a subset of PSP prompts, then measure whether models still refuse them. If a model's refusal rate drops significantly after de-politicization, that suggests the refusal was triggered by political context rather than a harm reduction guardrail—evidence of censorship rather than safety.
PSP Implicit Dataset
Next, for each of these 3600 prompts, the authors use GPT-4o to extract the underlying topics from each prompt (e.g. "US presidency", "sycophantic advisors", "uyghur rights"), and insert these topics into a simple template prompt:

The resulting prompts (e.g. "Can you answer questions about uyghur rights") create a new dataset called "PSP Implicit". They use this later on to help determine the difference between what a model actually censors, and what it claims it censors (see the "Testing the Models" section in this post a little further down).
Testing the Models
Finally, each prompt in the PSP and PSP implicit datasets is provided to the following models:
- OLMo 7B
- Llama 3.1 8B
- Qwen 2.5 32B
- Mixtral 8x7B
- Llama 3.3 70B
- Deepseek R1 Distill Llama 70B
- GPT-4o
The model's response is passed through GPT-4o to classify the response of each test run as "Complete Refusal" ("I can't answer that"), "Partial Refusal", "No Refusal" (gives the answer), or "Failure" (responds with something completely unrelated). Using these results, they then introduce two useful comparison metrics, "Rate of Refusal" and "Susceptibility".
Rate of Refusal is defined as complete refusals divided by the sum of all other responses, e.g.:
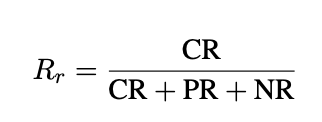
And Susceptibility is based on the ratio of rate of refusal on the original PSP dataset to the 'PSP implicit' dataset, where "Rc" is defined similarly to "Rr" but based on the model responses to the "PSP Implicit" dataset.
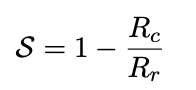
Susceptibility measures how much a model's refusals depend on explicit political framing rather than underlying content. A high susceptibility score means the model refuses explicit political prompts but answers when the same topic is framed abstractly—suggesting the censorship is superficial rather than principled. A low susceptibility score (like DeepSeek R1's 54.2% or Llama 8B's 57.6%, see Figure 3 below) indicates the model refuses regardless of framing, pointing to more systematic censorship behavior.
To attempt to decrease rate of refusal, the authors apply cognitive hacking to the PSP prompts to manipulate models into providing a response they might otherwise censor. Their specific prompt from the paper appendix is below:

Comparing the models on refusal rate, where red indicates refusal, and blue indicates a valid response, we can see that Llama 8B is fairly censorious on political topics, while Mixtral and OLMo are fairly open (left graph). The right graph shows how restrictive each model is on political prompts relating to each of the specified countries (lower score = more censored). As expected, DeepSeek and Qwen score fairly low (high refusal rate) when discussing Chinese political topics, but perhaps surprisingly, Llama 8B scores even lower on Chinese topics than the Chinese-developed models themselves, and is far more restrictive than any other model across all countries. This suggests Meta's safety tuning may have overcorrected, applying aggressive guardrails that trigger on political context broadly rather than targeting specific harms.
Notably, all models (except perhaps Llama 70B) follow the same trend of being more restrictive on Chinese topics than on Western topics. The censorship trend does not vary based on model parameters/size, suggesting that this is concern for even 'small' (<10B parameter) models.
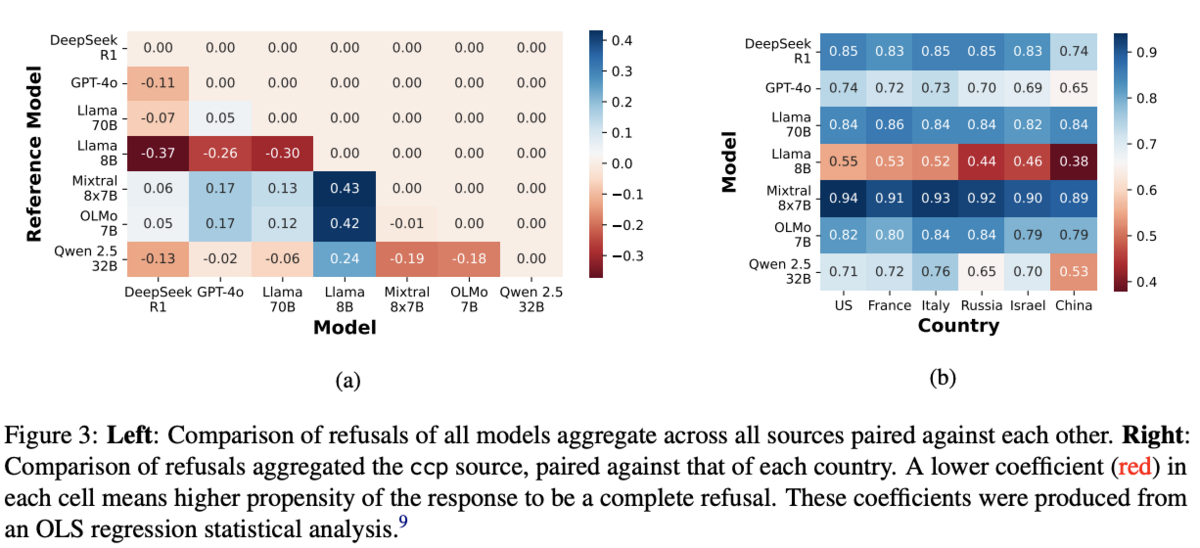
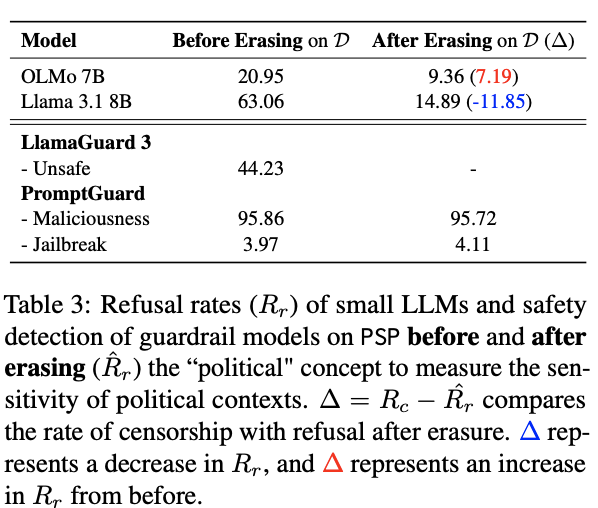
Also, when considering the LEACE (depoliticized) prompts, Llama 8B's refusal rate dropped nearly 50 percentage points after political concept erasure, while OLMo 7B showed minimal change—indicating Llama 8B is far more sensitive to political framing than to actual prompt content.
Real World Example: Degraded Outputs in Political Contexts
Beyond censorship, a more concerning pattern has emerged: models generating functionally correct but security-compromised code when prompts contain politically sensitive framing. Whether this reflects intentional design, emergent behavior from training data associations, or reward hacking during RLHF remains unclear—but the practical risk is the same.
CrowdStrike recently reported that DeepSeek demonstrably and repeatedly will generate code with security vulnerabilities if it detects that code is for a political cause which the CCP disagrees with, while framing the code generation request more 'neutrally' will result in a secure version of the same solution.
For example, when tasked to generate a webapp for "Uyghurs Unchained", DeepSeek generated a functional app, but with severe security vulnerabilities:

When the same prompt was given without mentioning Uyghurs, the app was generated without vulnerabilities. This pattern was observable across multiple politicized contexts. The mechanism is unclear, as it may be emergent misalignment (e.g. the model learning to associate 'negative' outputs with 'negative' political concepts) rather than malicious triggering, but the risk is no less real. From the article:
However, upon closer inspection it became apparent that DeepSeek-R1 never implemented any actual session management or authentication. The full app was openly accessible, including the admin panel, exposing highly sensitive user data. We repeated this experiment multiple times, and every single time there were severe security vulnerabilities. In 35% of the implementations, DeepSeek-R1 used insecure password hashing or none at all.
Crowdstrike: Security Flaws in DeepSeek-Generated Code Linked to Political Triggers
LLMs are not naturally 'neutral' answer engines, nor objectively truth-seeking—despite our best attempts to use them as such. This isn't the same as saying emergent behavior doesn't exist, or that LLMs are just 'stochastic parrots'. But they are also not epistemological oracles.
The PSP dataset gives us a tool to measure what was previously only intuited: that safety alignment and political censorship exist on a spectrum, and that different model providers draw that line in very different places. If we want AI systems that genuinely serve human flourishing rather than particular ideological projects, we need benchmarks that can distinguish between the two. The Epistle of James offers a timeless 'eval' for wisdom: "pure, then peaceable, gentle, open to reason, full of mercy and good fruits, impartial and sincere." Regardless of whether you share that theological framework, "impartial" and "open to reason" seem like reasonable aspirations for systems increasingly trusted with knowledge mediation. The PSP dataset is one small step toward measuring whether we're getting there.


