

The general problem of 'wanting to execute a series of operations in a specific order, with arbitrary dependencies between those operations' applies across a number of domains, and as a result, a number of domain-specific frameworks have emerged around this concept. MLOps/LLMOps biases heavily towards "ETL" style workflows, while DevOps typically focuses on CI/CD.
The domain-specific language of each framework will reflect its focus, but the underlying abstractions are often functionally similar.
Regardless of use case, these orchestration frameworks tend to center around a few key concepts, outlined below.
Directed Acyclic Graphs (DAG)
As a type of graph which doesn't contain loops, and where every node is directionally related to every other node, DAGs are naturally suited to modelling the relationships and dependencies between 'step-by-step' operations required to accomplish a larger goal.

A key difference between a DAG and a simple 'pipeline' is that (traditionally) a pipeline is often purely linear execution, where a DAG contains an arbitrary number of task forks and convergences. This isn't true, fo
Most frameworks model the 'blueprint' for the workflow to run as a DAG, and include some concept of an 'instance' of that workflow (an 'actual execution'). Some frameworks allow the DAG to be explicitly modelled, while others 'implicitly' build it from 'requirements' embedded in individual task definitions - as in the Luigi task definition shown below:
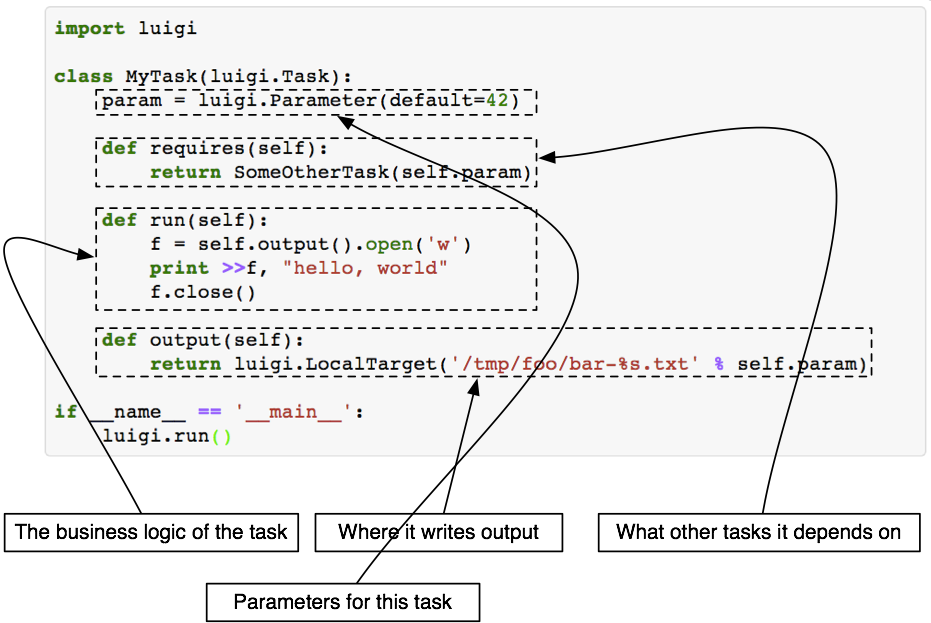
Tasks and Pipelines
A "task" represents a node within a DAG - an arbitrary 'body of work' that executes in some order (with some dependencies on other tasks or conditions) defined by the DAG. Typically, the task represents an atomic set of steps that either completes successfully (and provides a successful artifact on completion), or fails. From Apache Airflow's documentation: "You should treat tasks in Airflow equivalent to transactions in a database. This implies that you should never produce incomplete results from your tasks." Following this advice makes tasks easier to reason about (if the task succeeded, the output is comprehensible and complete, otherwise, the output is not useful). Some examples of tasks that meet this criterion are:
- Extracting data from a datastore (Postgres, DynamoDB, etc)
- Sending notification emails
- Parsing a set of data (the output being the parsed/validated data, or failure otherwise)
- Transforming data using a simple Python script
- Executing an arbitrary transformation on input data using software running inside a Docker container
- Running compute-intensive inference on a set of validated data
You should treat tasks in Airflow equivalent to transactions in a database. This implies that you should never produce incomplete results from your tasks.
A Pipeline encapsulates tasks and creates relationships between them - the pipeline represents a "DAG" which connects the tasks in a way that makes dependency clear. Below are some examples of how what concepts internally map "Tasks" and "Pipelines" in a variety of frameworks:
| Framework | "Task" Abstraction | "DAG of Tasks" Abstraction | Native Definition Format |
| Apache Airflow | Task | DAG | Python with custom decorators |
| KubeFlow | Component | Pipeline | Python with custom decorators |
| Gitlab Pipelines | Jobs | Pipeline | YAML |
| Tekton Pipelines | Task | Pipeline | YAML (Kubernetes Custom Resources) |
| Luigi | Task | "Workflow" (Not explicitly exposed - implicit through dependency definitions between tasks) | Python with custom decorators |
| Argo Workflows | Task | "Workflow" (can be expressed as a DAG or just 'steps' for simpler workflows) | YAML (Kubernetes Custom Resources) |
As is evident above, some frameworks require and expect Kubernetes to be present, others assume the developers are fluent in Python, and others (Gitlab Pipelines) define a new domain-specific language based on YAML. Understanding how Tasks will be defined, and where they will be deployed plays heavily into what is the 'right' tool for a given team.
Framework Intent
The intent of a framework is also exposed by what is 'easy' to accomplish within it. Yes, you could use Tekton to model an LLMOps/MLOps workflow (pulling data from BigQuery, splitting it into training/eval sets, and training a model), but Tekton provides features to allow each task to easily execute in a completely heterogenous environment (think Task A running a licensed Windows application in a Windows container, followed by Tasks B and C which use Alpine Linux and a thin Node build, for instance). But, its likely that something that heavy (where new 'tasks' must be defined as Kubernetes CRDs) is less ideal for a Data Engineering team that simply wants to define their tasks and pipeline in Python, and get going fast.
A simple DAG from the Airflow Tutorial is below, defining three tasks (t1, t2, t3) and ensuring that t2 and t3 'depend on' t1 (via the statement in the final line):
from datetime import timedelta # The DAG object; we'll need this to instantiate a DAG from airflow import DAG # Operators; we need this to operate! from airflow.operators.bash_operator import BashOperator from airflow.utils.dates import days_ago # These args will get passed on to each operator # You can override them on a per-task basis during operator initialization default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': days_ago(2), 'email': ['[email protected]'], 'email_on_failure': False, 'email_on_retry': False, 'retries': 1, 'retry_delay': timedelta(minutes=5), # 'queue': 'bash_queue', # 'pool': 'backfill', # 'priority_weight': 10, # 'end_date': datetime(2016, 1, 1), # 'wait_for_downstream': False, # 'dag': dag, # 'sla': timedelta(hours=2), # 'execution_timeout': timedelta(seconds=300), # 'on_failure_callback': some_function, # 'on_success_callback': some_other_function, # 'on_retry_callback': another_function, # 'sla_miss_callback': yet_another_function, # 'trigger_rule': 'all_success' } dag = DAG( 'tutorial', default_args=default_args, description='A simple tutorial DAG', schedule_interval=timedelta(days=1), ) # t1, t2 and t3 are examples of tasks created by instantiating operators t1 = BashOperator( task_id='print_date', bash_command='date', dag=dag, ) t2 = BashOperator( task_id='sleep', depends_on_past=False, bash_command='sleep 5', retries=3, dag=dag, ) dag.doc_md = __doc__ t1.doc_md = """\ #### Task Documentation You can document your task using the attributes `doc_md` (markdown), `doc` (plain text), `doc_rst`, `doc_json`, `doc_yaml` which gets rendered in the UI's Task Instance Details page.  """ templated_command = """ {% for i in range(5) %} echo "{{ ds }}" echo "{{ macros.ds_add(ds, 7)}}" echo "{{ params.my_param }}" {% endfor %} """ t3 = BashOperator( task_id='templated', depends_on_past=False, bash_command=templated_command, params={'my_param': 'Parameter I passed in'}, dag=dag, ) t1 >> [t2, t3]
Compared to the Tekton approach, which explicitly separates out tasks and pipelines into separate YAML files (defining Kubernetes custom resources), and is 'executed' by applying the custom resources to a given Kubernetes cluster, the Airflow approach is arguably more ergonomic for native Python developers (and avoids bringing Kubernetes-awareness into the context of a task pipeline). Luigi takes a similar 'Python-first' approach.
Observability
The monitoring available to detect errors and pipeline execution state execution status also tells us something about the intended users - many frameworks include dashboards, but how those are deployed, accessed, and interacted are useful selection criteria when choosing a tool.
Kubeflow offers a polished dashboard, and the existence of Katib Experiments as a top-level navigational element tells us that ML developers are a strong contingent of the expected userbase:
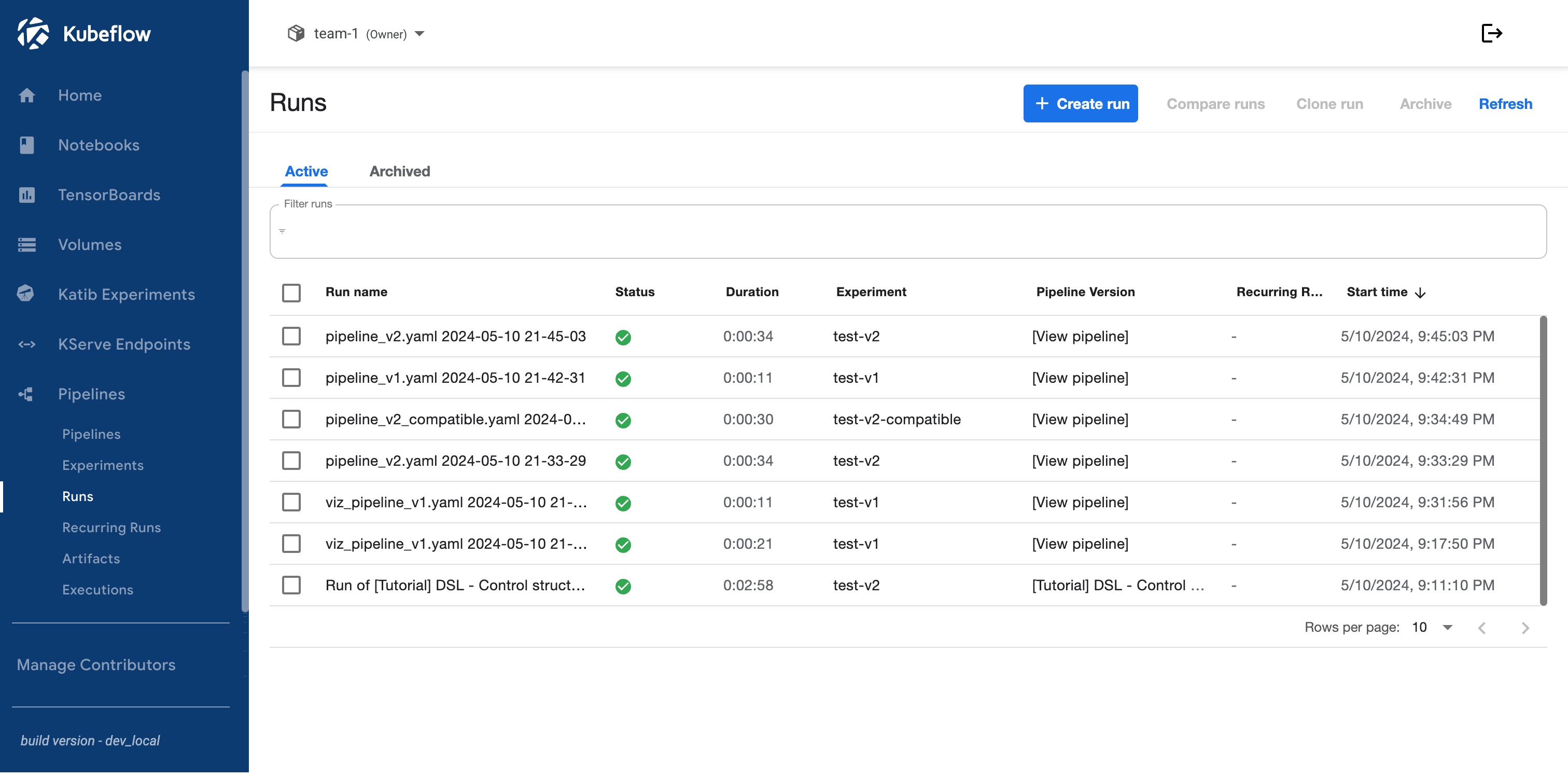
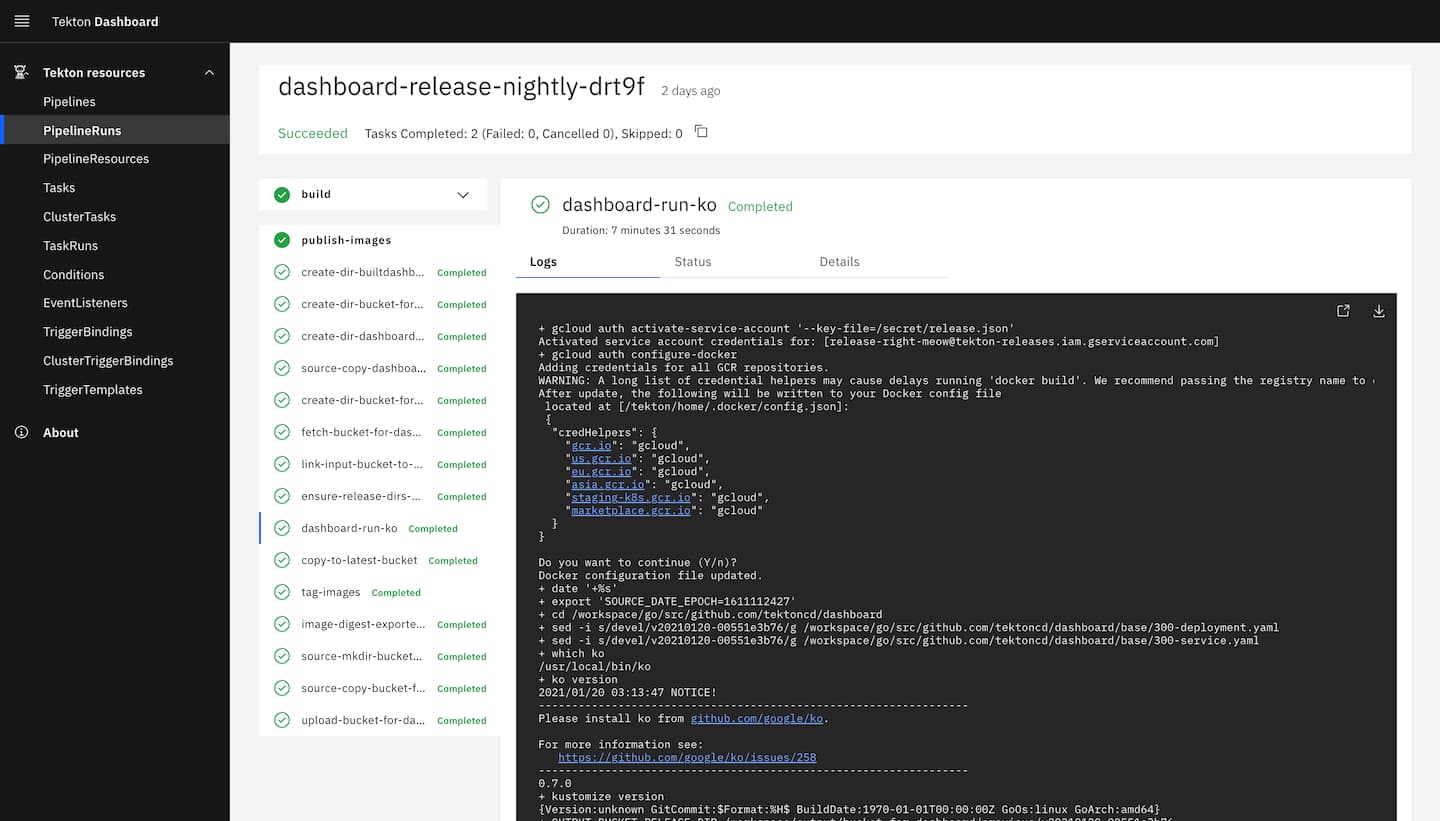
Contrast this with the Tekton Dashboard, which is very focused around the Kubernetes-driven model of custom 'resources'. Specifically, note the way that "Pipelines" and "PipelineRuns" are two distinct objects at the same level, where in Kubeflow "Pipelines" and "Runs" are under the overarching "Pipelines" heading. This is a direct result of the Tekton model being tightly coupled to Kubernetes concepts and primitives.
Selection
Ultimately, many of these tools can 'do the job' from a technical perspective, but its worthwhile selecting a tool that the development team enjoys using, without importing additional context and concepts at lower levels of abstraction than necessary. Does the data science team need to know about Kubernetes CRDs? If not, will you write custom wrappers to hide those details from them if using Tekton? How does that compare to the helper logic you'd write for Airflow?
Additional References


