

In the recent Relation-Rich Visual Document Generator for Visual Information Extraction paper, the authors note that while LLMs and MLLM (multimodal large language models) have provided general 'document understanding' over uploaded document images, 'semi-structured' documents are still a problem. These kinds of documents include invoices, receipts, and other documents that might have 'sensitive information', and thus are lacking in available data models (unlike academic papers, which are readily available as training inputs). The authors introduce the "Relation-rich visual Document generator" (or "RIDGE"), which attempts to capture the relationship between layout and content in documents in a way that would be expensive to do with manual, human annotations, and then demonstrate that fine-tuning existing VQA models with these synthetic documents dramatically improves performance on existing real-world document datasets.
Open Set vs Closed Set Datasets
As helpful background, lets look at existing document datasets used for VQA tasks. The Form Understanding In Noisy Scanned Documents ("FUNSD") is an open-set dataset, containing 199 documents that look like this:
As is evident from the examples above, these are rather 'freeform' annotation categories. There isn't a distinction between what 'kinds' of questions might exist, or how those might vary across documents in different domains. As a result, open-set examples are ideal for building 'generalized' Evisual understanding capability across a variety of real-world documents. Constrast that with a closed-set dataset like the Consolidated Receipt Dataset ("CORD"):

The CORD dataset breaks each document into bounded regions that have an explicit, predetermined, domain-specific 'class', such as:
- total.total_price - total price
- menu.nm - name of menu
- menu.discountprice - discounted price of menu
From the image above, you can see that the words "BLACK PEPPER MEATBALL" are recognized as three independent bounded word entities, making up a "menu name", in group ID 3. This level of domain-specific detail in the annotations is ideal for accuracy-critical systems (like receipt parsing for expense reports) at the loss of general document understanding.
RIDGE Document Content Generation
The first step in the RIDGE approach is the document content generation. RIDGE approach generates both the structured document itself, and annotations that allow a downstream model to be fine-tuned on document understanding tasks. Practically, a document title is given to an LLM, which is prompted to generate the body of the document in "Hierarchical Structured Text" format, a simple tag-based format which wraps the content in <content> tags, uses <hX> tags for paragraphs, and uses ":" and "-" to indicate key:value relationships and nesting (parent/child) relationships. An in-context one-shot example is given to help the LLM understand these rules, as shown below:

After the document content is generated in the "HST" format (the structure shown in the orange one-shot exemplar above), the annotations are extracted from it, which provide key/value linkages between fields like "Name: John" or "Total Price: $200". The annotations also capture nested relationships (inherent in the HST document structure). Then, the annotations are given to the Layout Generation steps below.
Content Driven Layout Generation Model (CLGM)
Now that we've got structured text representing a document, how do we place it in X-Y dimensions on a page? RIDGE approaches this by providing the text as 'entities' in the following format, where width and height are fixed as the 'layout canvas' size. The novel piece to note here is the "FILL_X" mask tokens - the bounding box is not determined, and its the job of the CDLG step to take the serialized data below, and predict the value of those mask tokens, which represent the bounding box for each text entity:
{"width":W,"height":H,"entities":[ {"text":t1,"box":["<FILL 1>"]}, ..., {"text":tN,"box":["<FILL N>"]}]}
But how does the model learn to infer the correct bounding boxes? In section 4.1, the paper indicates that OCR annotations from XFUND, FUNSD, and HUST-CELL are used alongside those images, and Google Vision API is used to obtain OCR results for the RVL-CDIP dataset. This data is serialized into the format mentioned above, and random permutations are applied to re-order the elements in the 'entities' array, so that the LLM only learns how to infer layout from content text without implicitly noticing what else is 'nearby' a given text block in the training data.
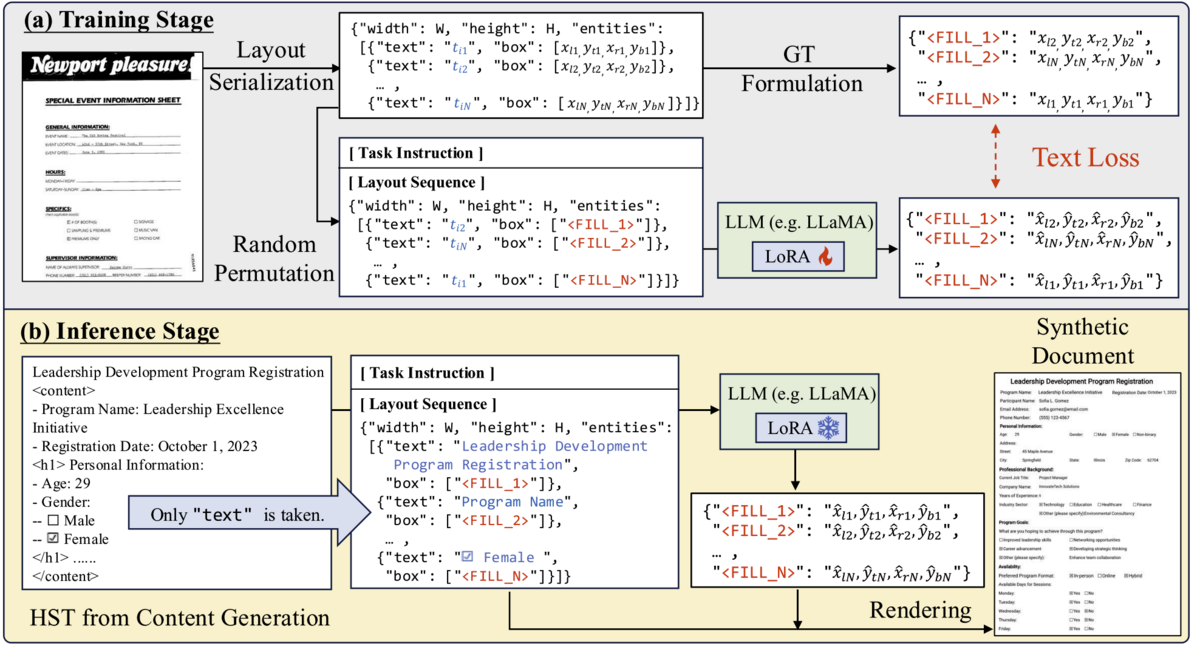
At inference time, the CLGM has already been trained on 100k+ 'real' document layouts for what are possible bounding box locations for text given a specific width/height canvas size, and it will infer an appropriate document to generate. Some examples of documents generated by RIDGE are shown below, to give an intuition of what it can do today

Performance
Okay, so given generated document images from RIDGE, how do we use them to improve document understanding for an existing LLM?
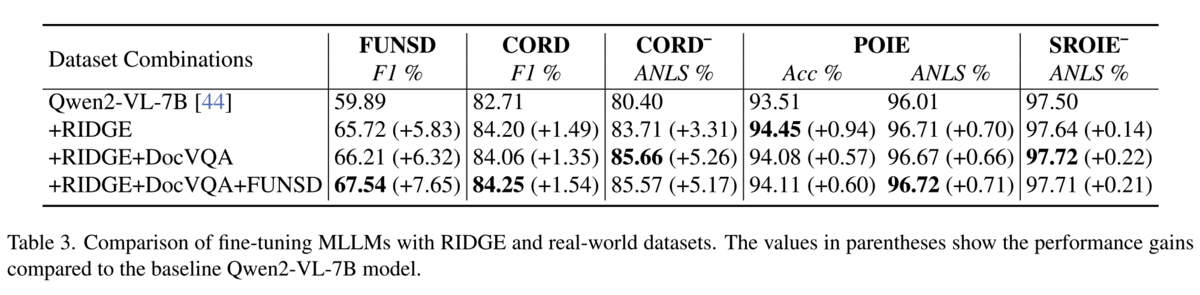
It turns out, having generated documents with annotations (remember the HST document structure from earlier?) is a powerful fine-tuning input to give multimodal models a better understanding of real-world document structure. Specifically, its worth noting that improvements are higher in open-set datasets, which the RIDGE document structure better represents. The researchers also explore domain-specific improvements via "RIDGE-DS", though, which involved generating annotations that better capture field labels like "price", and including those in the context for layout generation.
Takeaway
Improving models might mean spending time collecting better input data, but increasingly, its possible to frame problems in a way that allows better synthetic data to be part of the solution. RIDGE ultimately improves the performance of LLMs on document understanding tasks by creating a new tool to generate fine-tuning inputs for a specific domain of interest. If you're working with form-like documents, RIDGE (once they release the code) could prove a helpful source of synthetic data for fine tuning a model.


