

As we enter 2025, predictions of agentic AI abound, while exactly what 'agentic' means is still fairly context dependent.
For our purposes, lets treat 'agentic' as an AI system that autonomously modifies the state of an external environment (physical world, a codebase, etc) to achieve a specific goal (typically stated in natural language, although domain-specific examples outside of natural language exist), and possesses a way to detect changes to that environment, so the system can measure progress towards or away from a stated goal. This implies the model has some form of 'tool use' (in order to modify an external environment, and observe the effects of those modifications). For example, we might ask a robotic agentic system to "wash all of the cups in the kitchen and put them away", a travel agentic system to "find and book a flight using my Avianca points in June that is no more expensive than I paid last year", or "Identify, by calling and emailing, which resorts have ski programs for kids under 10, and rank them in order of cost" (and expect the agentic system to figure out and execute the intermediate steps without intervention). Latent.space recently highlighted a thread with some working definitions along these lines (specifically, not chatbots).
However, the above definition says very little about how best to build these agentic systems - and this provides plenty of room to explore the tradeoffs of different implementations (assuming that cost is a factor, and we don't converge to a single AGI-capable LLM at a low cost anytime soon). One approach, Reflexion: Language Agents with Verbal Reinforcement Learning, uses three separate LMs and two memory blocks (long and short term) to provide the overall 'system' (which we'll consider an 'agent' here) with the ability to improve based on specific, evaluative feedback from previous attempts. The Reflexion approach goes beyond static in-context prompting decision-making frameworks like ReAct (Reason + Act) by allowing the agent to 'improve' over a number of serial attempts at the problem.
As a reminder, ReAct provides a series of thought->action->observations in response to a user prompt. For example, the prompt "Question: Aside from the Apple Remote, what other device can control the program Apple Remote was originally designed to interact with?" might result in the following LM generated dialogue:

LANGUAGE MODELS"
Overall Flow
Reflexion's LMs are broken down into an "Actor", an "Evaluator", and a "Self-Reflector". These models are initialized with few-shot examples that match their specific roles (explained below). At any given timestep, the Actor decides on and outputs an action (which modifies the environment), and the observation of the changed environment goes into the short-term memory (to create a 'trajectory', which is simply the action/observation pair). The Evaluator model also receives the 'trajectory', and determines if the observed state is 'correct', or if further work is required.
The evaluator output, combined with the associated trajectory, is given to the Self-Reflection model, which uses those to update the long-term memory with a 'reflection'. And then, the Actor takes another pass at the task (initiating another 'trial'), but uses the updated long and short term memory as context inputs.
One of the key differences between Reflexion and a single-LM approach with reasoning prompting (like ReAct) is that Reflexion attempts to explicitly evaluate, learn, and adapt its approach after each 'trial' run, based primarily on the reflective feedback in the long-term memory.
The 'verbal' nature of the reflections also make this approach less of a 'black box' - similar to chain-of-thought or ReAct prompting, the 'thought process' of the agent is made externalized to better understand why certain decisions were made. This explainability aspect is crucial both for debugging and for ensuring the system remains interpretable as it learns.
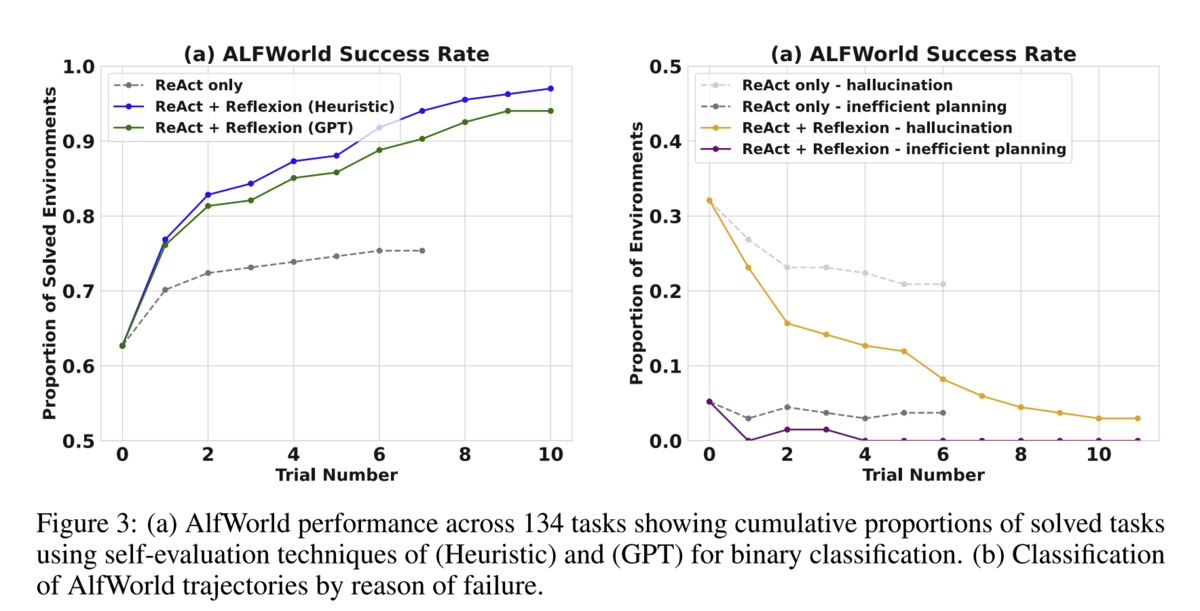
Why does this all matter? Reflexion allows an agent to improve its results iteratively when compared to a standalone 'think->act->observe' approach like ReAct. In the figure below (showing performance on ALFWorld), notice that when Reflexion is used, number of solved problems *increases* as the trial number increases (left graph), and the number of failures *decreases* accordingly as the trial count goes up. ReAct levels off. In other words, Reflexion allows the agent to learn from its failures.
Short and Long Term Memory
The distinction between the two types of memory mentioned in the paper is perhaps better described by their purpose than duration. The 'short-term' memory in Reflexion is just the history of 'trajectories' (action/observation pairs) that the system has taken so far, or a history of state changes. At first, the short-term memory is empty. After taking an action, that action and the resulting observation are stored in the story term memory for that 'trial'.
The long-term memory is the cumulative output of the 'self-reflective' agent, or a set of 'reflections', one for each trial. Again, at the first iteration of the Reflexion system, there is nothing in the long-term memory. After the actor takes an action and the observation associated with that action is evaulated by the "Evaluator", the evaluation result (which can be a simple 'correct/incorrect', a scalar value,etc), the "Self-Reflector" takes the evaluator output and the action/observation pair, and stores a 'verbal reflection'.
Crucially, in subsequent trials, this 'verbal reflection' is available to the Actor model, which uses it to refine the next chosen action as in the example below. Note the "Reflection" section at the bottom - this is the information that will be stored in the "Long Term" memory for "Trial #1".

Actor Model
The Actor model is "built upon a large language model (LLM) that is specifically prompted to generate the necessary text and actions conditioned on the state observations". To determine what action to take, the actor takes short term memory (the history of past actions / observation pairs for each 'trial') and long term memory (the history of reflection outputs for each 'trial' run) as context, and attempts to generate an action to move towards a correct answer. In the first trial, the Actor can only rely on its prompting (which might be ReAct, CoT, etc), and the input question. After the first trial, the Actor has access to the Reflection and Trajectory data for every previous trial, and it can use this information to refine its next action. In the example shown above, notice that in Trial #2, the Actor correctly determines that it needs to identify a 'series of battles', based on the reflection data from the first trial.
Evaluator Model
The Evaluator model scores the text and actions generated by the Actor model by computing a reward score that "reflects its performance within the given task context". This can be a simple tabular lookup, and doesn't necessarily need to be an LLM. In the code implemented by the paper authors for the HotPotQA task, the Evaluator model is a function that takes the current 'answer', an 'answer key', and returns a boolean true/false representing if the answer matches the expected one from the key:

Obviously, this evaluation method only works if the answer is known ahead of time, but its possible to swap in any evaluation here - as long as it can provide directional guidance to the self-reflector model (is the output trending towards correct or incorrect, better or worse, etc. Some other evaluation examples are shown below - the model is flexible, and the evaluation depends on the problem domain.

Self-Reflection Model
The Self Reflector/Reflection model receives the result of the evaluator model, as well as the last trajectory (the actions/observations taken in this trial step). Given this information, the self-reflection model takes a 'reflection' prompt. The prompt below is the one used by the paper for the Alfworld runs (the 'few-shot examples' referenced can be found here)
query: str = f"""You will be given the history of a past experience in which you were placed in an environment
and given a task to complete. You were unsuccessful in completing the task.
Do not summarize your environment, but rather think about the strategy and path you took to attempt to complete the task.
Devise a concise, new plan of action that accounts for your mistake with reference to specific actions that you should have taken.
For example, if you tried A and B but forgot C, then devise a plan to achieve C with environment-specific actions.
You will need this later when you are solving the same task. Give your plan after "Plan". Here are two examples:
{FEW_SHOT_EXAMPLES}
One of the Reflexion prompts used for Python programming tasks is below:
"You are an AI Python assistant. You will be given your previous implementation of a function, a series of unit tests results, and your self-reflection on your previous implementation. Write your full implementation (restate the function signature)."
From the above examples, we can see that the Self-Reflection model prompt varies based on the task the Reflexion agent is being tailored for, similar to the task-specific Evaluation model. In other words, there is not a 'one-size-fits-all' Reflexion agent, the individual models need to be adjusted based on the problem domain.
The output from the Reflexion model (based on the above prompt, and provided context) is then provided to the Actor agent, and the cycle continues (another 'trial' is executed). This process continues until the Evaluator deems the 'observation' of a given trial a success, or a max trial count is exceeded.
Next Steps
As noted in the paper, the 'ability to specify self-corrections is an emergent quality of stronger, larger models'. So, don't be surprised if this approach fails on relatively small models (the example the authors give as a model which is too small to perform Reflexion is starchat-beta, a 16B parameter model tuned for coding assistance).
But, if you have the capacity to run multiple iterations on a larger (e.g. GPT-4, Sonnet 3.5) model, and you're working on a reasoning, code generation, or QA task, you can expect significant performance gains using Reflexion. For example, HumanEval on Python code improves from 80.1 (base GPT-4) to 91.0 using Reflexion, and similar gains over existing SOTA approaches are present in HotPotQA and ALFWorld tasks.
If you want to start exploring self-reflection in your own projects, LangChain already has some good starting resources, with a specific step-by-step tutorial dedicated to reflexion. Perhaps you'll even end up following the paper's closing advice (in "Limitations") to "extend the memory component of Reflexion with more advanced structures such as vector embedding databgases or traditional SQL databases", to provide a RAG-enabled 'context lookup' of 'similar problems' rather than starting the agent with a blank memory on each new problem.


