

Training Data and Scaling
"We’ve now exhausted basically the cumulative sum of human knowledge … in AI training"
Elon Musk via TechCrunch (summarizing a Mark Penn X interview, January 2025)
The 'knowledge' available to Large Language Models is inherently limited by their training set, which primarily consists of publicly available, human-generated text. This data is not inexhaustible, and the rate at which it can be consumed is fundamentally greater than the rate at which new, human-originated text can be created. In other words, we're running out of internet to ingest. The full Epoch AI paper outlines these concerns in more detail, but by their estimates, the fount of novel text will run dry between 2026 and 2032 (assuming a 'profit maximizing' policy by AI developers):
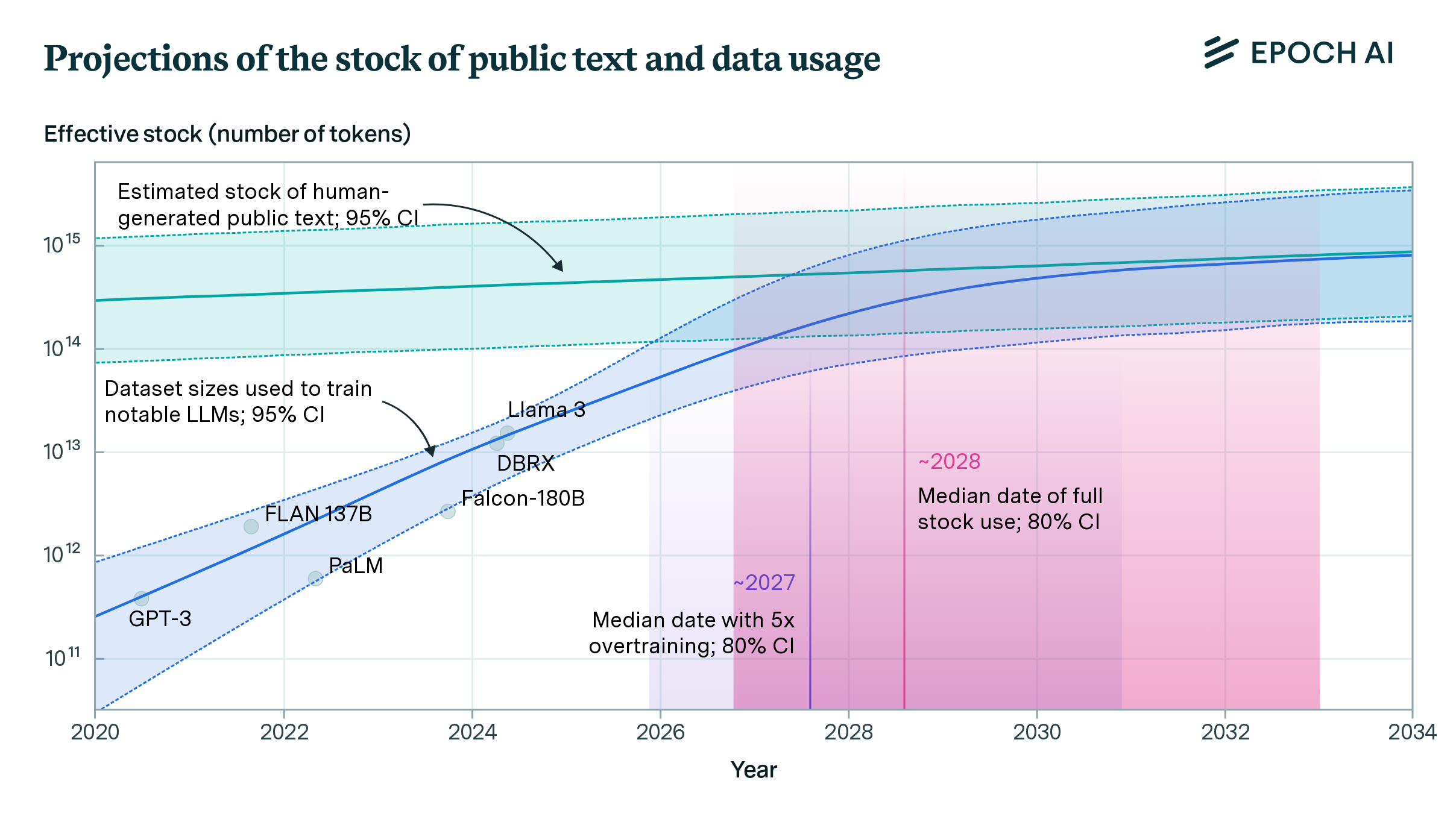
Approaches that attempt to address the problem (allowing continued scaling without novel data) include:
- Synthetic data generation (risking homogeneous, unrealistic outputs)
- Multimodal learning (train on images/video)
- Expanding into domain-specific, private data
Lets dig into the last bullet in that list, starting with RAG.
Retrieval-Augmented Generation - the "Second Curve"
RAG, whether enabled via semantic vector search, knowledge graphs, or some combination of these and other techniques, ends up effectively expanding the 'knowledge' that a model has beyond its pretrained parameters. By enabling deeply domain-specific documentation to be easily referenced by a model (effectively via a RAG 'tool call' to perform a similarity search for relevant documents), models can begin to respond to information that is unlikely to be well-represented in their training data, such as deeply technical internal product specifications, nuanced corporate policies, or even private data that should only be accessible to the user making the query.
Of course, the amount of retrieved data that can be integrated is limited by the models context window, so reranking models can be used to help select 'the most relevant documents to the overall query'.
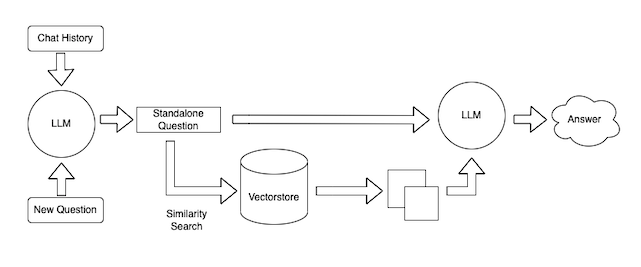
Guangwei Zhang, a researcher bridging the gap between Computer Science and History, writes that if Scaling Laws enabling massive improvements on public data was the 'first curve' of capability enhancement, RAG represented the 'second curve'. Specifically, RAG improved performance (accuracy) on knowledge-intensive tasks by expanding what models could access, but it fundamentally remained a retrieval and recall system.
While RAG excels at finding and surfacing information related to a users query, it doesn't instruct an LLM on how to reason about that information within domain-specific contexts. A legal RAG system tied to a general purpose LLM might retrieve relevant case law, but it doesn't understand the nuanced way lawyers think about precedent, jurisdiction, or case strategy. A medical RAG system can find relevant research papers, but it lacks the clinical reasoning patterns that experienced physicians use to synthesize symptoms, test results, and treatment protocols.
This gap between information access and expert reasoning arguably spurred the development of Agentic AI, reasoning models, and what Zhang coins as the 'third curve': Knowledge Protocol Engineering.
Knowledge Protocol Engineering
In Knowledge Protocol Engineering, the work of improving models shifts from increasing what they 'know' towards how to interact with data within a particular domain. Specifically, Zhang writes:
"KPE aims to elevate an LLM’s capabilities from factual recall to a higher order of abstract and procedural reasoning, addressing a critical gap left by the previous two curves."
At a high level, this is thinking less 'how do I adjust prompts to achieve my outcome', and more 'how would I train a new member of my organization to do the tasks I do day-to-day?'.
While MCP (or any tool-use protocol) enables KPE, KPE is not simply 'giving the model more tools'. Assuming a model has the ability to read documents (think most agentic code CLIs, like Claude Code or Gemini CLI), whats missing 'out of the box' is the domain-specific 'tribal knowledge' about what tools to use, in what order, and what decision trees matter for determining 'whats next' when completing a task in that domain.
Workflow Engineering vs Raw Tools
Traditional AI tools often provide raw capabilities—access to APIs, databases, or computational functions. KPE emphasizes workflow engineering: designing tool interactions that guide users through expert-level reasoning processes.
The difference is that when the tools themselves encode a domain-specific workflow, the model becomes more useful and reliable in that specific domain - by taking actions and making decisions using the same 'framework' that a domain expert would.
The act of building an MCP server (defining specific tools, prompts, etc) is a form of encoding domain methodology into an executable knowledge protocol. The KPE paper, gives a helpful example in Section 3.2 of the difference between KPE and traditional agentic solutions, for the task of "Find all genes in the human genome that are associated with Alzheimer's disease and are also targeted by the experimental drug 'Pharma-X'":
- Standard Agentic Approach: An agent might try to query a gene database for “Alzheimer’s” and a chemical database for “Pharma-X” separately. It might struggle to formulate a plan to correctly intersect these two complex datasets.
- KPE Approach: A Knowledge Protocol is built from a standard bioinformatics pipeline
document. It specifies the workflow:
1. Query Disease-Gene Association: Use the ‘GeneDB’ to find all genes linked to
“Alzheimer’s disease” (Concept ID: ‘C0002395’).
2. Query Drug-Target Association: Use the ‘DrugBank’ to find all gene targets of
“Pharma-X” (DBID: ‘DB12345’).
3. Intersect Results: Perform a ‘JOIN’ or set intersection on the results from the previous two steps to find the common genes.
The protocol provides the LLM with a clear, unambiguous, and validated scientific workflow, transforming a complex query into a series of executable steps.
Each of the tools/steps above might also leverage LLMs themselves, where they are iterating on the 'answer' with the primary model until the desired level of 'quality' (again, domain specific) is met. This also overcomes context and token limits that can occur if the primary model is asked to do all of those tasks 'at once' in a single large CLAUDE.md or AGENTS.md file.
There is no 'magic number' of tools in the workflow, nor does it need to be fully sequential - but the concept is that the way these tools are designed exposes a 'mental model' of how the LLM should approach the problem, versus giving it generalized guidance like 'always consider edge cases' or 'go figure out what tools to use on your own' (which might not align with what a domain expert would actually do).
The Future of Domain Specific Models
KPE represents a fundamental shift in how we think about AI capabilities. Rather than building increasingly large models trained on ever-more data, we're moving toward systems that embody the thinking patterns of domain experts.

As foundation models converge on 'similar' performance across broad benchmarks, the differential value of narrow, deep model performance will increase. "Knowledge Protocol Engineering" is one way to think about how that will occur. Will we see "Protocol Compilers", that take company policy documents, email chains related to specific business problems (and solutions), and task specific guidance, and 'automatically' generate a company specific domain expert model? Does that lead to one 'canonical' model for a company, which then can be used to generate smaller, even more niche (but company aligned) downstream models for each organization in the company?
In any case, it looks like the future is not 'more static information', but 'how and why we use that information in specific ways'.


