

Increasing Dimensionality
While Text-to-3D and Image-to-3D AI models proliferate, the resulting 3D models are often roughly similar to the described (via image or text) entity, but lack dimensional accuracy, elide key details, and develop the resulting model as a whole entity, ignoring the nuances of physically distinct elements. This isn't to say they're not useful - but like all tools, there are limitations.
If you're unfamiliar with the power of these models, heres an a recent (interactive demo) of Direct3D-S2, converting a single image of the Burj Khalifa into an approximated 3D OBJ model, which can be edited in downstream 3D asset software.
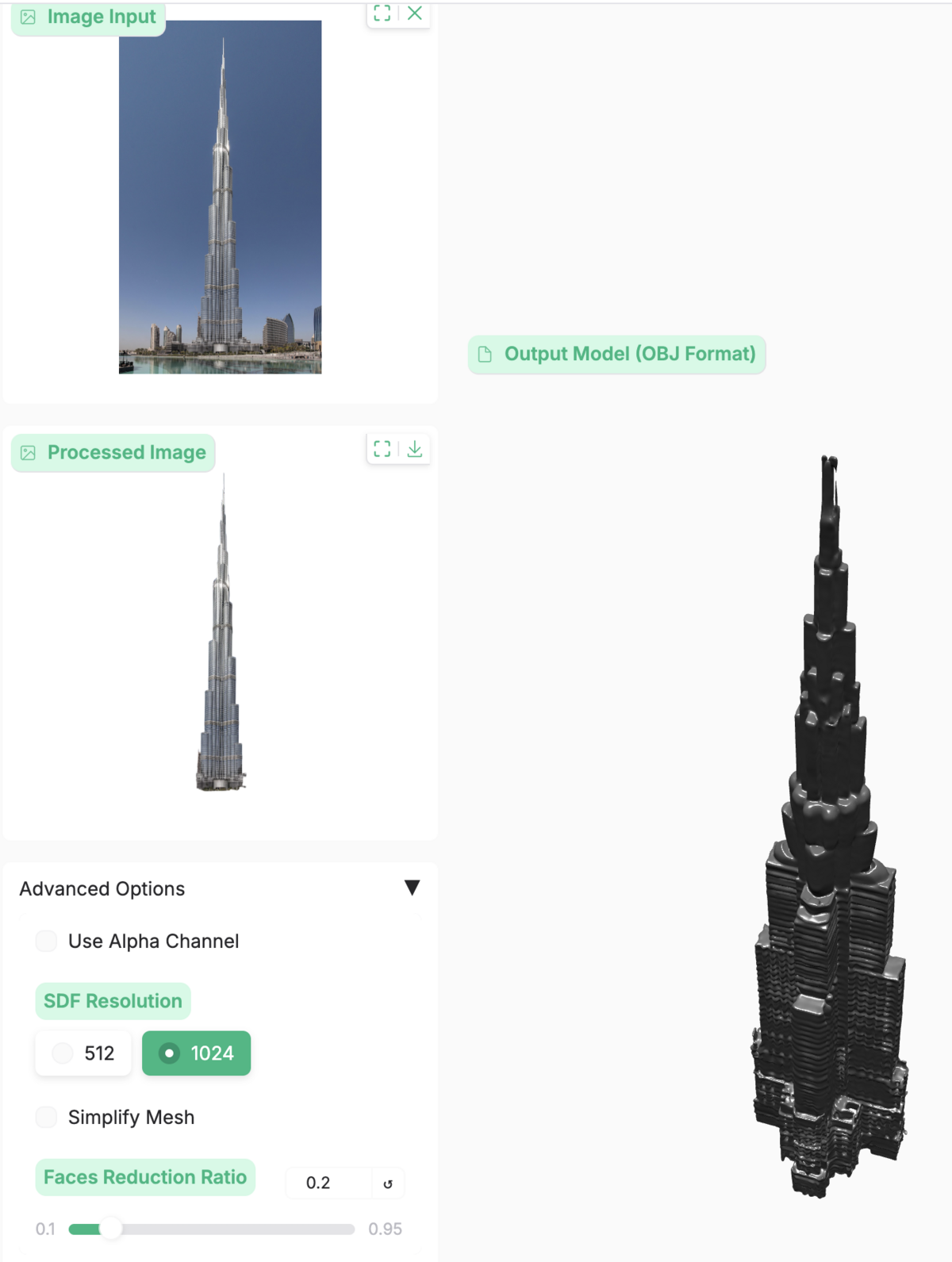
While the 3D render is visually similar to the Burj, upon close inspection, you'll notice the staggered faces of the actual Burj are reduced down to simple, equal setbacks. These staggered setbacks in the real world Burj aren't incidental, they are a critical piece of the design, per Skidmore, Owings, & Merrill:
The setbacks are organized in conjunction with the tower’s grid: the stepping is achieved by aligning columns above with walls below to provide a smooth load path. This enabled construction to proceed without the typical delays associated with column transfers. At each setback, the building’s width changes. The advantage of the tower’s stepping and shaping is, in essence, to “confuse the wind.” Wind vortices can never coalesce because the wind encounters a different building shape at each tier.
Skidmore, Owings, & Merrill (SOM.com)
To some extent, inference and ambiguity between the actual building represented in a 2D image and any rendered 3D representation based only on that 2D image are expected1 - we're increasing dimensionality, and volume, depth, and hidden surfaces need to be inferred (in the above case, from patterns in the training data around building structure, including the expectation that the building is roughly symmetrical). While other work to extract dimensions and specifications from 2D engineering drawings exists, we're after something a little different here - a way to convert an image into a 3D representation, while preserving meaningful part distinctions, and some relative dimensional accuracy between those parts.
Beyond the Surface
In Part123: Part-aware 3D Reconstruction from a Single-view Image, explicitly recognizes some of the limitations we saw above with existing models:
...all the existing methods represent the target object as a closed mesh devoid of any structural information, thus neglecting the part-based structure, which is crucial for many downstream applications, of the reconstructed shape. Moreover, the generated meshes usually suffer from large noises, unsmooth surfaces, and blurry textures, making it challenging to obtain satisfactory part segments using 3D segmentation techniques.
In their alternative solution, rather than going directly to a 3D geometry from the input image, the Part123 team takes the following steps:
- Using a diffusion model (SyncDreamer), generate a set of 16 multiview-consistent images from the initial input image. These would include other views (side, aerial, 45 degree, back, etc), generating information not present in the initial image
- Perform 2D segmentation on these multiview images, using SegmentAnything
- Reconstruct a 'part-aware' 3D model based on the segmented parts from multiple images in (2)
While SegmentAnything provides a versatile, generalizable way to detect 'parts' from the multiview images, it introduces a new problem - since each 'multiview' image is passed through the segmentation pipeline separately, the resulting segmented parts might not be completely consistent in each image. Figure 2 from the paper illustrates this - note that the back is segmented as a separate part in the first two images, but merged into the rest of the body in the third image:

The number of detected parts also varies across the images - clearly, these inconsistencies present a problem when trying to determine which parts to 'lift' into a 3D space. The Part123 approach addresses this by adding a 'part segment branch' to a NeuS neural network, which outputs high dimensional feature vectors for each 3D point (beyond just color and density). They then use contrastive learning, leveraging using the mask pixels from the SAM segmentation output across multiple views. Specifically, SAM masks that are the same across multiple views will pull 3D points in those views 'closer' in feature space, and SAM masks that are different in multiple views will push 3D points within those masks 'further apart' in feature space. Imagining that we provided the Burj Khalifa to this pipeline, this might look like:
- SAM identifies 'window' pixels across multiple views of the Burj Khalifa
- The model learns that all 'window' 3D points should have similar feature vectors
- A glass 'window' becomes very different (in terms of feature vector embedding distance) from a 'wall' or 'setback'
The paper illustrates the 'sampling strategy for contrastive learning in Figure 4, below:

For every query pixel in a given view, a positive sample is selected from the same mask, and a negative sample from a different mask in the same view. Since this is happening in the context of NeuS, these query pixels are associated with an underlying 3D point - so the 'contrastive learning' from each view allows training the same 3D point from multiple viewing angles.
Once this model is trained to provide each 3D point in the model with a high dimensional feature vector (based on the SegmentAnything masks as described above), a graph is built to create connections between 2D segmentation masks that appear in multiple image views. For example, if a 'window mask' in View #1 corresponds to a 'window mask' in View #2, a connection between these nodes is made in the graph. This is repeated for all masks across all views. Then, simply counting the connected components gives the number of distinct 3D parts. In the Burj example, this might look like (simplifying part count here, assuming all windows are 'one part', e.g.):
- View "Front": Has masks for [windows, wall, floor-1-setback]
- View "Side": Has masks for [windows, wall, floor-2-setback]
- View "Top": Has masks for [roof, wall, base]
This results in 6 connected components - the windows, the walls, the floor-1-setback, the floor-2-setback, the roof, and the base. Via this clever application of graph theory, no user input is needed to specify part count, and consistency with the number of parts detected by SegmentAnything across all views is preserved.
A major advantage of Part123 over approaches that require annotated 3D datasets is the inherent generalizability of SegmentAnything - rather than relying on 3D-specific training data, they've found a novel way to leverage an existing, versatile 2D segmentation solution to generate 3D representations. Section 2 in the paper provides a good survey of other recent approaches to 'lift' 2D images into 3D spaces, where a few other approaches which also attempt to generalize based on 2D segmentation models are mentioned (e.g. PartSLIP).
Reconstruction Quality
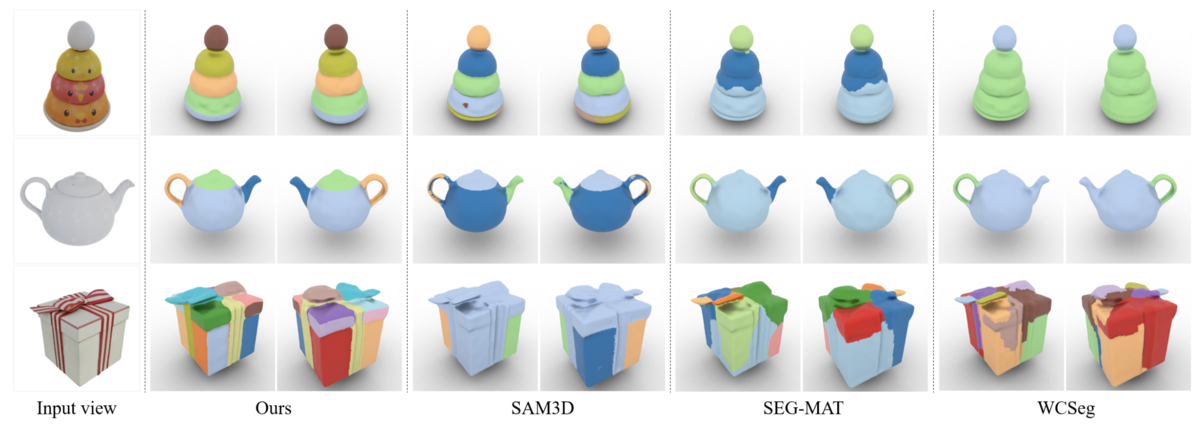
Lets take a look at how Part123 performs in single-image 3D reconstruction versus other techniques, looking to section 4. Figure 6 provides a visual comparison of a few approaches - note in particular how the teapot lid and handle are identified as distinct parts, as well as the clearly delineated 'parts' of the gift box:
In the part segmentation process, Part123 provides a configurable 'overlapping ratio'. To calculate this ratio, they project a given part segmentation mask from one view (Ma) onto second view (Mab), and compute how much the resulting projection overlaps with a second 'target' mask in that second view (Mb). The amount of overlap is then compared to a specific threshold ratio, and if the overlap is above that threshold, it indicates that Ma and Mb are masks for the same part.
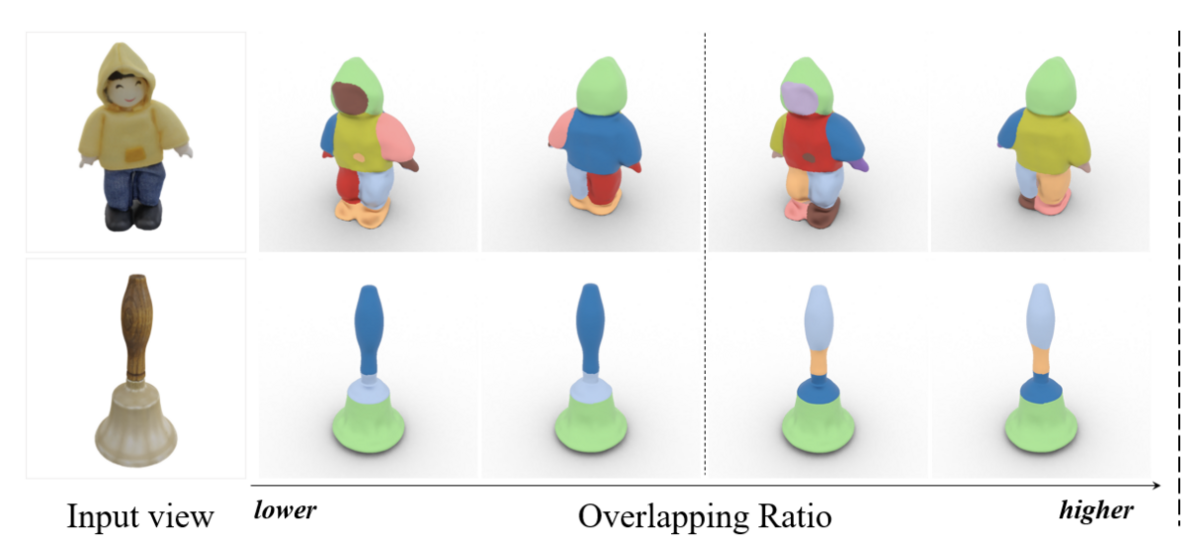
So, by decreasing the threshold ratio, parts that only 'somewhat' overlap are still considered (merged) into a single part in the final representation, and by increasing the threshold ratio, the resulting 3D model will have more distinct 'parts'.
To visualize this, see the feet of the boy in the left/'lower' overlapping ratio portion of the diagram in figure 7:
But critically, the threshold overlapping ratio provides a generalized way for end-users to adjust the segmentation for a specific application with different segmentation detail requirements, without needing to retrain or adjust model hyperparameters.
Takeaways
Building 3D models from 2D models is a difficult problem, particularly if you're interested in preserving structural details (like distinct parts), and Part123 provides a thoughtful way forward in this domain by combining existing strong 2D segmentation models (SegmentAnything), an algorithm to create consistency between multiple views, and adding contrastive learning to an existing 3D generative model (NeuS) to introduce 'part awareness' as a learned feature.
Footnotes
1. And in the other direction, going from 3D to 2D means projection and information loss, whether in a map projection that preserves correct directionality at the expense of relative landmass sizes, or the 3D-to-2D 'unfolding' imagined by Cixin Liu). A single view/image of a 3D model is necessarily a lossy representation.



{kind=link}