

Hallucinations and Grounding
Hallucinations (both intrinsic and extrinsic) are a known failure mode for LLMs, making them risky for production systems in high-stakes fields like law and finance. The standard solution is grounding—connecting the model's output to a reliable knowledge source—but this isn't a silver bullet.
Simply having a reliable knowledge source isn't enough. The way that a model queries the source is crucial. Consider the challenge of multi-step reasoning, as highlighted in Figure 1 from the GraphSEARCH paper. A model might fail if it only performs a "shallow retrieval" and doesn't follow a chain of facts, which becomes evident when observing the model behavior when given a complex, four-entity query. As the figure demonstrates, simply having a prebuilt knowledge graph with all of the necessary information to correctly answer a query does not guarantee a correct answer:
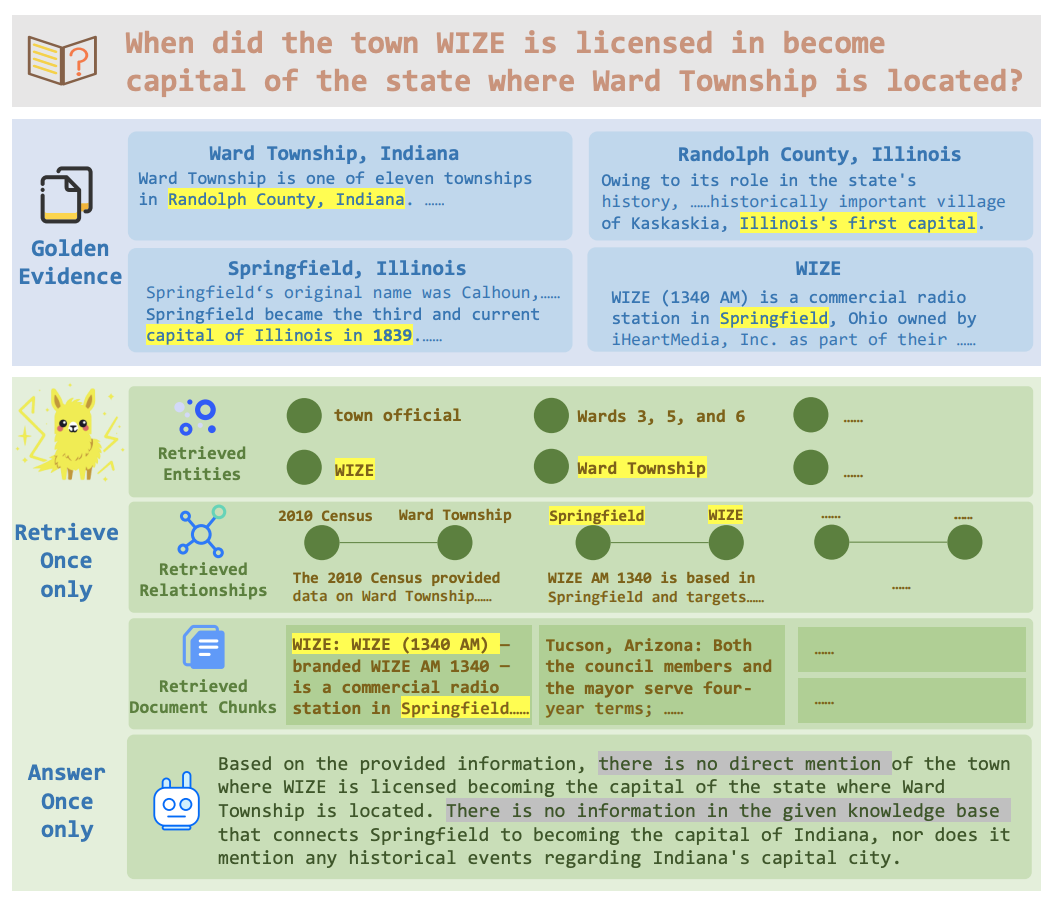
Even though the knowledge graph clearly contains the information necessary to answer the question, the single-round nature of the retrieval (what the authors call 'shallow retrieval') means that the multi-step link between WIZE and the date when Springfield becomes the state capital is overlooked. The 'retrieve once only' and 'answer once only' constraints prevent the model from exploiting richer, multi-hop relationships that are present in the grounding data. Here's another way to visualize these limitations, where the generated answer lacks information that exists in the provided context:
![```mermaid graph TD %% Input Layer Query['🔍 User Query'] %% Traditional GraphRAG Components Query --> Retrieval['⚡ Shallow Retrieval<br/>(Single-pass)'] %% Data Sources (separated, not well-integrated) GraphData['📊 Pre-constructed<br/>Graph Data<br/>(Underutilized)'] TextData['📄 Text/Document<br/>Chunks'] %% Retrieval connects to data sources Retrieval -.->|'Limited graph<br/>traversal'| GraphData Retrieval -->|'Primary focus'| TextData %% Processing TextData --> Evidence['📌 Retrieved Evidence<br/>(Often incomplete)'] GraphData -.->|'Minimal<br/>contribution'| Evidence %% Generation Evidence --> LLM['🤖 LLM<br/>(Language Model)'] LLM --> Answer['💡 Generated Answer'] %% Styling classDef queryClass fill:#e1f5fe,stroke:#01579b,stroke-width:2px classDef dataClass fill:#f3e5f5,stroke:#4a148c,stroke-width:2px classDef processClass fill:#fff3e0,stroke:#e65100,stroke-width:2px classDef outputClass fill:#e8f5e9,stroke:#1b5e20,stroke-width:2px classDef limitClass fill:#ffebee,stroke:#b71c1c,stroke-width:2px,stroke-dasharray: 5 5 class Query queryClass class GraphData,TextData dataClass class Retrieval,Evidence processClass class LLM processClass class Answer outputClass %% Annotations for limitations Limitation1['⚠️ LIMITATION 1:<br/>Shallow retrieval misses<br/>critical evidence'] Limitation2['⚠️ LIMITATION 2:<br/>Inefficient use of<br/>graph structure'] Limitation1 -.->|'Issue'| Retrieval Limitation2 -.->|'Issue'| GraphData class Limitation1,Limitation2 limitClass```](https://editor.blogmaker.app/web/assets/uploads/5d8501168ade097059d9ee519a6feee0.png)
The Modular Search Pipeline of GraphSEARCH
Instead of a single retrieval step, GraphSEARCH decomposes the initial problem into smaller queries, refine and build dependencies between those subqueries, execute the queries, and build back up a logical 'reasoning chain' to tie the answer back to the reference data, even across multiple logical links and relationships. They describe a 'dual-channel' approach, which just means that the following steps are performed in parallel across both semantic/text (traditional RAG) and graph knowledge stores, before combining the results of each parallel retrieval path to generate the final answer.
This pipeline consists of six steps, in two phases:
Phase A: Iterative Retrieval
- Query Decomposition: Break the input query into smaller, atomic queries, each looking at a "single entity, relationship, or contextual dependency". This decomposition occurs via a separate prompt for text-based and graph-based queries, with few-shot examples given in the prompt context, such as (from Figure 9 in the paper):
Main Query:
How many times did plague occur in the place where the creator of The Worship of Venus died?
Sub-queries:
{{
"Sub-query 1": [("The Worship of Venus", "is created by", "Entity#1")],
"Sub-query 2": [("Entity#1", "died at", "Entity#2")],
"Sub-query 3": [
("Plague", "occur in", "Entity#2"),
("Plague", "times of occur", "Entity#3")
]
}}
2. Context Refinement: The result of each executed sub-query is context, and the context refinement step attempts to increase the value of this retrieved context by removing irrelevant or tangential information (so that in subsequent steps, only the most salient information is included). Again, from Figure 9, the prompt for this step for the graph retrieval path:

3. Query Grounding (or 'query rewriting'): As some sub-queries may depend on the results of other (previous) queries, this step prompts an LLM to take the queries with placeholders (e.g. "Entity 1"), and 'fill in' those placeholders with correct values based on the results of previous sub-queries. This is possible because the sub-queries are designed to be logically independent but semantically ordered, with one-way dependencies (a later query cannot provide information that informs an earlier query).
This process is iterative. After a sub-query is executed and its context refined, the pipeline uses the result to ground the next dependent query (Step 3) and continues the retrieval cycle until all sub-queries are resolved.
Phase B: Reflection Routing
4. Logic Drafting: Based on the grounded queries and the results to those queries, an LLM is prompted to create a reasoning chain that ties these sub-queries together in a logically coherent way that leads to an answer to the users original query. This step also identifies any 'missing pieces' (entities,relationships) by nature of placeholders remaining in the proposed logic chain.
5. Evidence Verification: Here, the logic chain generated in the "Logic Drafting" step is evaluated, checking for:
- Strictly grounded response data (is the logic chain only using data from the subquery results?)
- Is the logic chain complete, e.g. no unsupported leaps or missing steps?
- Are there any evidence gaps or speculative claims?
This step is using LLM-as-a-judge to check for hallucinations in the output of step (4), to ensure 'faithfulness' of the content of the answer to the content in the provided context. This is functionally similar to how Datadog implements hallucination detection in their LLM Observability feature,where they frame the problem as finding 'disagreements' between claims in the answer and claims in the golden/observed dataset:

6. Query Expansion: If the Logic Drafting (Step 4) or Evidence Verification (Step 5) steps identify missing evidence or logical inconsistencies, this step generates additional sub-queries to 'fill in' those gaps, updating the context available to reason from, and allowing iteration back to Step 4 to improve the proposed logic chain.
Results
By pairing the GraphSEARCH algorithm above with various RAG frameworks, the authors achieve better results than any of those frameworks alone, as well as standard RAG or vanilla LLM approaches. The authors evaluate across SubEM, A-Score, and E-Score, which represent:
- Substring Exact Match (SubEM): Higher value if the 'golden answer' was explicitly contained in the response, calculated as the count of queries submitted where the generated output contains the answer, divided by the total number of queries submitted.
- Answer Score (A-Score): LLM-as-a-Judge measuring correctness, logical coherence, and comprehensiveness
- Evidence Score (E-Score): LLM-as-a-Judge measuring relevance, knowledgeability, and factuality
The prompts for A-Score and E-Score are contained in Appendix F of the paper, and ask the evaluating LLM to produce a 0-10 score in three separate categories for each score:

While using a relatively small LLM (Qwen2.5-32B-Instruct) as the backbone, they demonstrate SoTA performance across a number of domains:
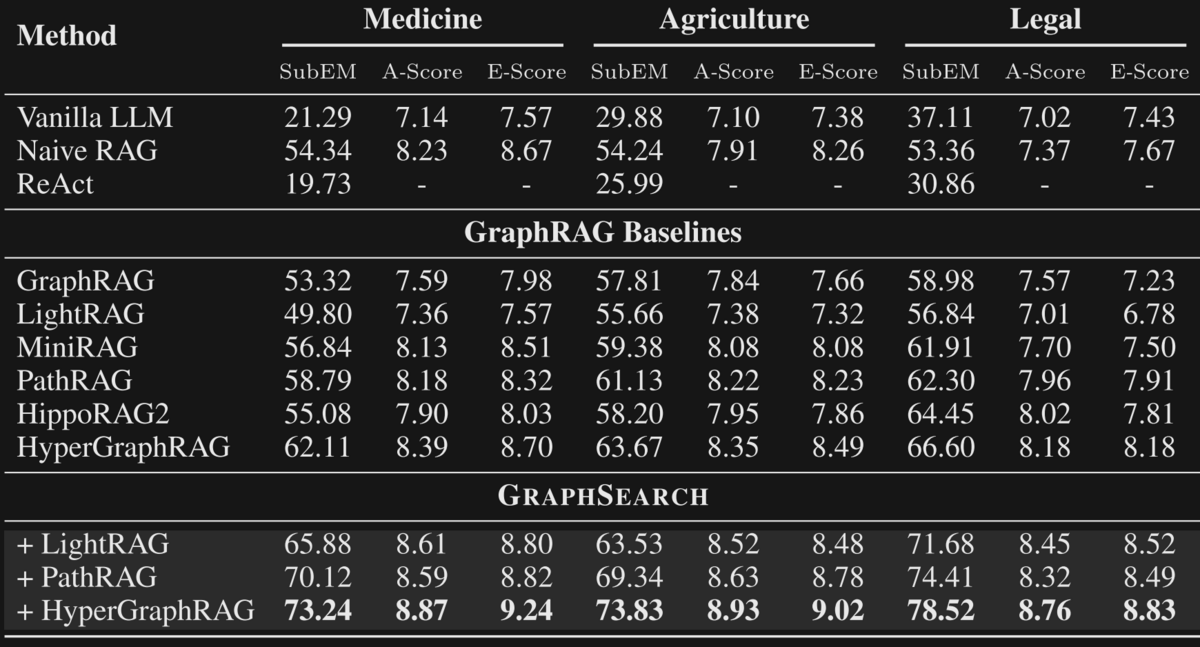
This provides practical evidence of the value of task decomposition and assignment to smaller language models in agentic workflows.
Still, a crucial piece of the puzzle is missing: the token cost and inference latency of these different approaches. While a smaller LLM implies lower costs, a full picture of token efficiency should be top-of-mind if you're considering deploying this method at scale.


